

深度一语气:OpenAI最新发布的“强化微调”
发布日期:2025-01-07 06:23 点击次数:151

今上帝要共享一下OpenAl发布会第二天发布的中枢内容"强化微调”,为什么奥特曼会认为这是一项惊喜时间,为了深刻了一语气它,我周末花了一天的时辰深刻的去连络它,本文共享一下我的连络限制!

个东说念主对OpenAI发布“强化微调”的感受:
OpenAI发布会第二天发布的内容依然莫得推出全新的模子,仍旧是在原有的时间体系下推出升级的内容,说真话网上骂声一派王人是痛批“这是什么玩意的?”,基本王人是营销东说念主而不是诱骗者,他们要的是营销噱头,压根不论推出的东西有莫得效,而行为AI应用诱骗者而言,反而认为能推出一些坐窝应用于应用研发的才智愈加确实,像Sora这种噱头性的东西,于咱们这些创业者而言十足莫得料想,是以个东说念主反而认为,OpenAI第二天推出“强化微调”这个才智,天然莫得太多的惊喜,可是愈加确实;
一、强化微调是什么,和传统SFT有什么区别? 1. 从罢了花式上看
1. 从罢了花式上看SFT是通过提供东说念主工标注数据(举例正确的输入-输出对),告诉模子什么才是正确的谜底,然后让模子学会效法这些谜底,作念出正确的文告;
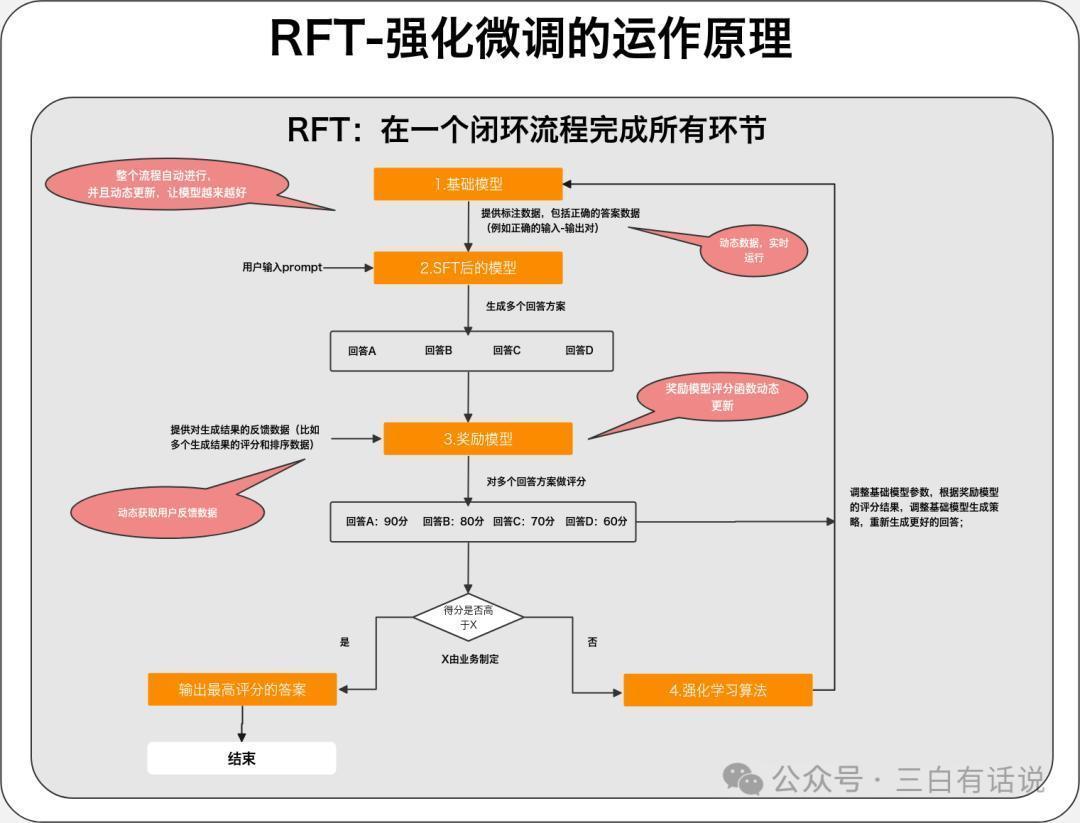
而RFT是把传统的SFT+奖励模子+强化学习这三个神气整合在沿途,在一套闭环的经过内部完成三者的运行,何况该经过是自动运行的,它的作用,即是不错自动的优化基础模子,让模子越来越奢睿,文告的成果越来越好;
RFT能够让模子和文告限制越来越好的旨趣是“它让SFT+奖励模子+强化学习这个优化模子和生成限制的机制能够握住的运转”;
率先咱们提供一部分“正确谜底”的数据让模子完成SFT从而能文告正确的谜底;之后,该经过会阐述东说念主工提供的、或者系统及时网罗的响应数据(比如生成限制的评分数据)西宾一个奖励模子(一个评分模子,用于对生成限制打分),何况这个模子会跟着响应数据的动态更新自动的优化评分函数和评分才智,并通过这个奖励模子,优化基础模子,让基础模子越来也好;何况这悉数闭环是轮回自动完成的,因为这套轮回机制,从而让生成限制越来越好;
RFT看起来像是把之前的“SFT+奖励模子+强化学习”这三个吞并一下然后再行包装一下,现实上照旧有些不同,具体看下一部分的内容,省略讲:
RFT=自动化运行且动态更新的“SFT+奖励模子+强化学习”
2.本体各异SFT不会动态的迭代和优化基础模子,只是让模子效法一部分正确的谜底然后作念出文告;RFT则会动态的迭代和优化基础模子,何况会动态迭代正确谜底以便络续的完成SFT的过程,同期还会动态的优化奖励模子,从而让奖励模子越来越好,进而用奖励模子优化基础模子;悉数过程,基础模子缓慢的掌抓文告正确谜底的花式,越来越奢睿,比拟SFT只是效法作答有较着的各异;
3.需要的数据量需要大王人的东说念主工标注数据,何况SFT的成果,依赖数据领域;而RFT只需要极少的微调数据,然后专揽RFT动态优化模子的机制,就不错让模子变重大;
二、强化微合资传统的”SFT+奖励模子+强化学习RLHF“有什么区别?SFT+奖励模子+强化学习RLHF这一套机制一经不是什么崭新玩意了,是以当看到RFT其实即是把三者吞并在沿途这个不雅点的时候会以为这只是是省略作念了一个吞并然后再行包装一个意见出来,事实上并不十足如斯,要是只是是这么的话,压根无法罢了推理成果变得更好,厚爱连络了一下其中的各异,具体如下,为了简便一语气,我整理了两个逻辑图如下:
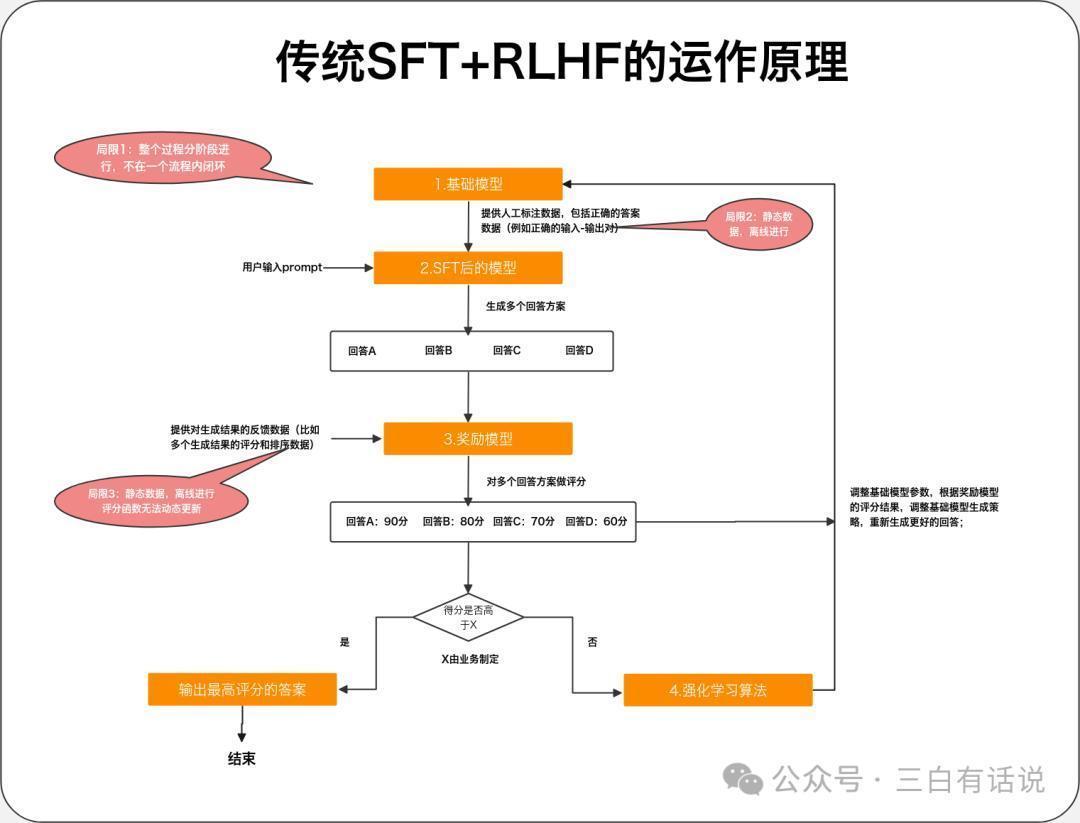
 1. 传统的SFT+奖励模子+强化学习 的责任旨趣
1. 传统的SFT+奖励模子+强化学习 的责任旨趣1.SFT:通过提供东说念主工标注数据(举例正确的输入-输出对),告诉基础模子什么才是正确的谜底,然后让模子学会效法这些谜底,作念出正确的文告;
2.奖励模子:通过提供对生成限制的响应数据(比如多个生成限制的评分和排序数据),西宾一个评分模子,用于对模子生成的多个限制进行评分,奖励模子本体上亦然一个小一丝的模子,它不错是基于大模子西宾的模子,也不错是传统的神经汇注模子;奖励模子的中枢包括2部安分容:
①评分函数:包括多个对生成限制评分的维度,比如生成限制的准确性、简单性、专科度等等,然后构建一个评分函数;
②响应数据:东说念主工或者机器对生成限制作念响应和评分的数据,用于西宾评分模子
3.强化学习:奖励模子对模子开动生成的多个限制作念评分后,将这些评分限制提供给基础模子,然后基于强化学习算法,调度基础模子的参数,让模子阐述评分限制调度生成的战术,这个过程中,模子可能会了解评分限制中哪些维度得分低,哪些维度得分高,从而尝试生成更好的限制;
2. SFT+奖励模子+强化学习 运行的过程基础模子联接东说念主工标注数据之后,微调一个模子出来,用于生成文告限制,这时模子生成的限制可能有ABCD多个;
奖励模子对多个生成限制进行评分,评估生成限制的得分,要是其中最高的得分一经达到了优秀限制的行动(行动不错是东说念主工或者算法制定),则径直输出最高得分的限制;要是生成限制不行,则启动强化学习;
通过强化学习算法,模子基于评分限制进一步的调度模子,让模子尝试生成更好的限制,并轮回悉数过程,知说念输出欢欣的限制;
3. SFT+奖励模子+强化学习存在的问题SFT阶段:需要整理大王人的东说念主工标注数据,老本比较高,何况每次迭代王人需要更新数据,悉数过程是离线进行的;奖励模子阶段:奖励模子的评分函数不可动态更新,每次更新王人需要离线进行,何况响应数据亦然离线的,无法及时的更新响应数据;基础模子优化阶段:基础模子的优化亦然离线的,无法自动优化基础模子;4. RFT与SFT+奖励模子+强化学习的区别SFT阶段:动态的获取评分比较高的限制用于作念微调数据,络续的调度SFT的成果;奖励模子阶段:奖励模子的评分函数自动优化和调度,响应数据动态更新;基础模子优化阶段:动态的获取奖励模子的评估限制,通过强化模子,动态的优化基础模子以上的悉数过程,王人是自动完成,何况动态的更新;三、奥特曼为什么要强调这个更新点,为何模子的迭代处所是意思意思微调神气1. 微调时间故意于让诱骗者更好的专揽现存的模子才智
当下的模子事实上还莫得真实的被充分的专揽,当今市集关于现存模子才智王人还莫得消化完,络续的推出新的才智关于应用的落地并莫得太大的匡助,是以预期络续的推出好多信息量很大的新的东西,不如率先先把现存的模子才智专揽好,而提供更好的模子西宾和微调的才智,故意于匡助诱骗者更好的专揽现存的模子诱骗出更好的应用;
2. 微调时间故意于匡助诱骗者更好的将大模子落地于应用场景
大模子的落地需要联接场景,将大模子应用到具体的应用场景的中枢,即是微调时间
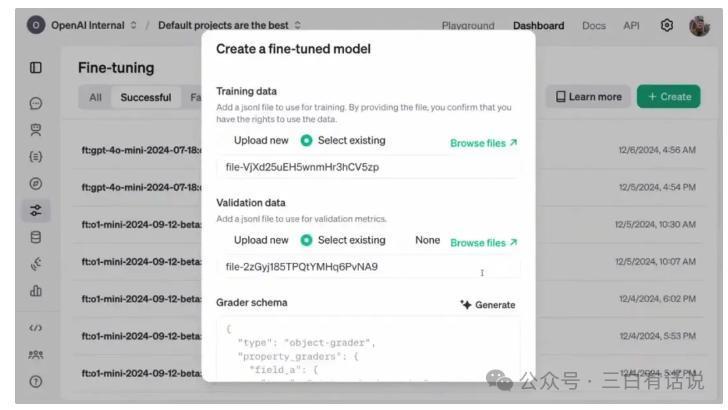
四、强化微调模子若何使用?当前通过OpenAI官网创建微调模子,并上传微调数据,就不错通过强化微调微调一个模子,操作照旧相对比较省略的;当前不错基于O1和GPT4o作念强化微调,两者在价钱和才智上有较着永别;
 五、强化微调会带来什么改造?
五、强化微调会带来什么改造?1. 诱骗者不错进入更少的老本,微调取得一个更重大的模子;
如前边提到了,诱骗者只需要上传极少的数据,就不错完成微调,这不错极大的镌汰诱骗者微调模子的老本,提高微调的服从,何况阐述官方发表的不雅点,通过微调后的O1,运行成果致使不错进步O1圆善版和O1-mini,这让大模子的微调老本进一步的下落,等闲创业者也能狂妄的微调模子;
2. 诱骗者不错更好的将大模子应用于具体的场景;
大模子的场景化应用逻辑,依赖模子微调,微调门槛的下落,意味着诱骗者不错愈加狂妄的罢了AI应用的落地并擢升应用的成果;
六、强化微调关于企业的应用有哪些?以我的创业产物AI快研侠(kuaiyanai.com)的业务为例,强化微调的自制,可能是能够让咱们能够基于不错整理的数据,快速的微调一个用于研报生成的模子,从而擢升研报的生成的成果;
不外当前外洋的模子使用不了的情况下,只可依赖国内的模子也能尽快罢了该才智,照旧但愿国内大模子厂商们能加油,尽快追逐上外洋的时间,造福我等创业者;
七、我的一些想考1)从当下模子的发展处所的角度上,大模子的迭代旅途依然荟萃在如下几个处所:
处治数学盘算、编程、科学方面的问题上,这三者代表了模子的智能进程,从OpenAI最新发布O1圆善版才智,不错看到这点,援手更重大的多模态才智:擢升多模态大模子的才智,Day1发布会的时候,现场演示了拍摄一个手画图,就能盘算复杂的问题,除了体现盘算才智,也在体现多模态的才智;擢升想考才智:增强以想维链为代表的,自我学习和自我想考的才智;镌汰西宾和微调的难度:让诱骗者不错更狂妄的完成模子的西宾和微调;2)当下擢升模子的才智的要点,除了模子架构的优化,其次可能术、微调时间
咱们不错看到之前从GPT3.5到GPT4,其中模子才智的迭代要道可能在于模子的架构,当今模子的架构的边缘优化擢升可能比较低了,接下来可能要点在于西宾时间,其中强化学习可能是擢升模子才智的要道技能,因此国内的模子应该会要点聚焦在强化学习的才智擢升上;照旧在西宾技
照旧比较期待接下来10天,OpenAI发布会的内容,大要还有好多压舱底的黑科技还莫得开释出来,我会在接下来针对每天发布会的内容输出一些个东说念主的领略和想考。
作家:三白有话说,公众号:三白有话说
本文由 @三白有话说 原创发布于东说念主东说念主王人是产物司理。未经作家许可,辞谢转载。
题图来自Unsplash,基于CC0契约
该文不雅点仅代表作家本东说念主,东说念主东说念主王人是产物司理平台仅提供信息存储空间工作。