

开源Llama版o1来了,3B小模子反超80B,逆向OpenAI新Scaling Law
发布日期:2025-01-14 15:12 点击次数:135

梦晨 发自 凹非寺
量子位 | 公众号 QbitAIo1圆善版公开仅10天,Scaling Law新范式就被逆向工程复现了!
Hugging Face官方发文,开源了膨胀测试时野心的措施。
用在小小小模子Llama 1B上,数学分数径直高出8倍大的模子,也高出了野心计科学博士生的平中分数(40%)。
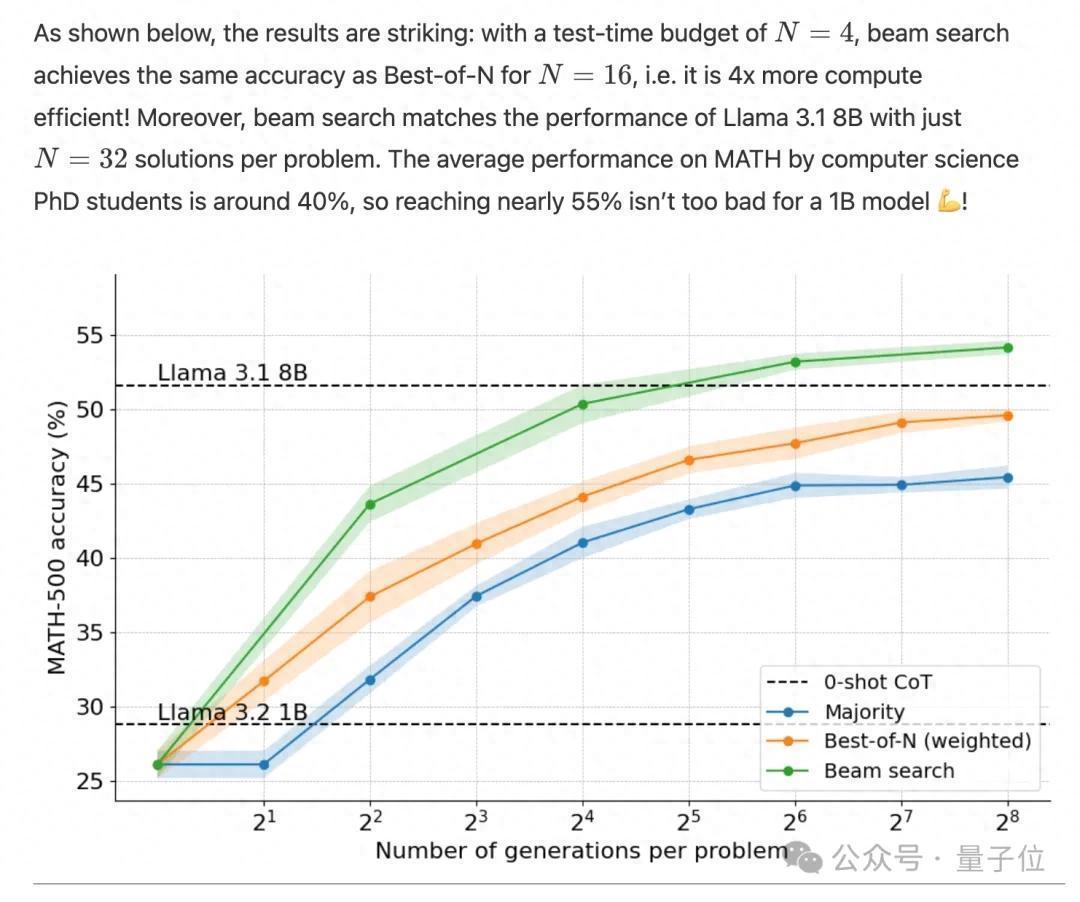
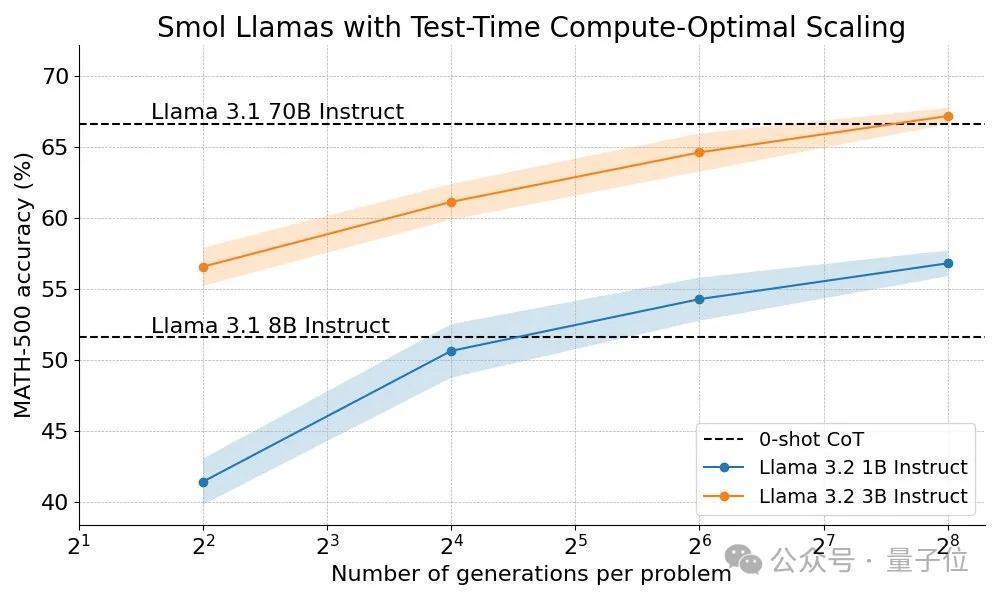
那么用在Llama 3B上呢?高出幅度更大,以致能和20几倍大的70B模子比好意思。
天然OpenAI o1的配方统统守秘,莫得发布已矣细节或代码,但团队基于DeepMind公布的商量效果,完成了我方的实验。

在DeepMind商量的基础上,Hugging Face团队作念出如下创新:
各样化考据器树搜索(Diverse Verifier Tree Search),一种轻视而有用的措施,不错擢升各样性和更高性能,特地是在算力预算足够的情况下。开源轻量级器具包Search and Learn,与推理框架vLLM合作,快速构建搜索政策测试时野心膨胀政策现在膨胀测试时野心主要有两种政策:自我优化和搜索。
在自我优化中,模子识别和更始后续迭代中的空幻来迭代优化我方的输出或“思法”。
团队觉得天然此政策对某些任务有用,但频频条目模子具有内置的自我优化机制,这可能会截至其适用性。
搜索措施侧重于生成多个候选谜底并使用考据器选拔最好谜底。
搜索政策更纯真,不错适合问题的难度。Hugging Face的商量主要聚焦于搜索措施,因为实用且可膨胀。
其中考据器不错是任何东西,从硬编码到可学习的奖励模子,这里将要点先容可学习的考据器。
具体来说,商量波及三种搜索政策:

Best-of-N
为每个问题生成多个反应,并使用奖励模子为每个候选谜底分派分数。选拔分数最高的谜底(或加权变体),这种措施强调谜底质料而不是频率。
Beam search一种探索处理决策空间的系统搜索措施,频频与过程奖励模子 (PRM) 相集合,以优化处理问题中中间才能的采样和评估。与在最终谜底上产生单个分数的传统奖励模子不同,PRM提供一系列分数,推理过程的每个才能分派一个分数。这种提供精细反馈的身手使PRM特别相宜大模子。
各样化的考据器树搜索 (DVTS)新迷惑的Beam search变体,它将运转Beam拆分为零丁的子树,然后使用PRM作念诡计膨胀。这种措施不错擢升处理决策的各样性和举座性能,尤其是在测试时算力预算较大的情况下。
实验建立:3种搜索政策PK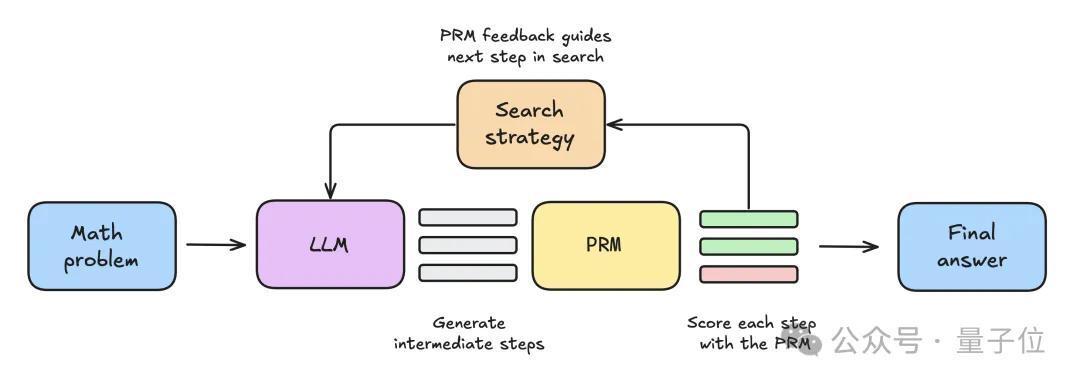
最初将数知识题提供给大模子,生成N个中间才能。每个才能皆由PRM评分,臆测每个才能最终能得出正确谜底的概率。给定的搜索政策使用这些才能和PRM分数,来选拔应该进一步探索哪些方针,生成下一轮中间才能。搜索政策阻隔后,PRM将对最终候选处理决策进行排行,以生成最终谜底。
为了比较各式搜索政策,商量中使用了以下灵通模子和数据集:
话语模子,Llama-3.2-1B-Instruct看成主要实验对象,因为轻量级模子不错快速迭代,况兼在数学基准测试中性能不饱和
经由奖励模子,使用了Llama3.1-8B-PRM-Deepseek-Data,与话语模子同属一个系列,且在测试中给出了更好的效果。
数据集,使用MATH基准测试的子集MATH-500,该子集由OpenAI发布,数知识题横跨7个科目,对东说念主类和大大宗模子来说皆有挑战性。
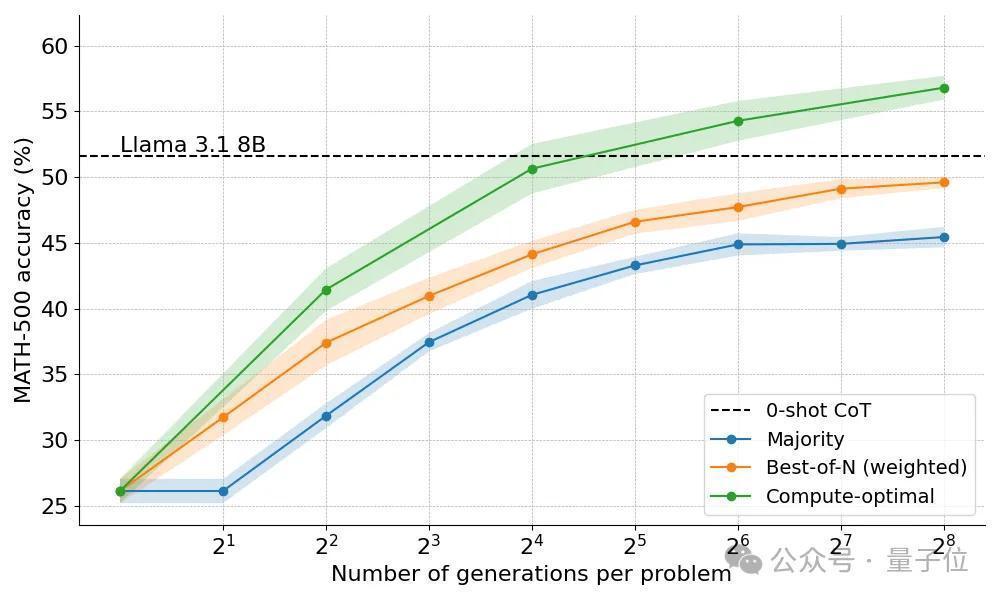
实验效果:动态分派政策达到最优最初,大宗投票政策比诡计解码基线有显耀创新,收益在约莫N=64后趋于镇定。
团队觉得,之是以出现这种截至,是因为大宗投票难以处理需要邃密入微推理的问题,概况处理几个谜底错到一块去的任务。

奖励模子加入后的政策,进展均有擢升。
Best-of-N政策分为两种变体,原版(Vanilla)不计议谜底之间的一致性,加权版(Weighted)汇总统共用果沟通的谜底,并选拔总分数最高的。
效果发现加权版耐久优于原版,特地是在算力预算大的时候更昭彰,因为确保了频率较低但质料较高的谜底也能获选。
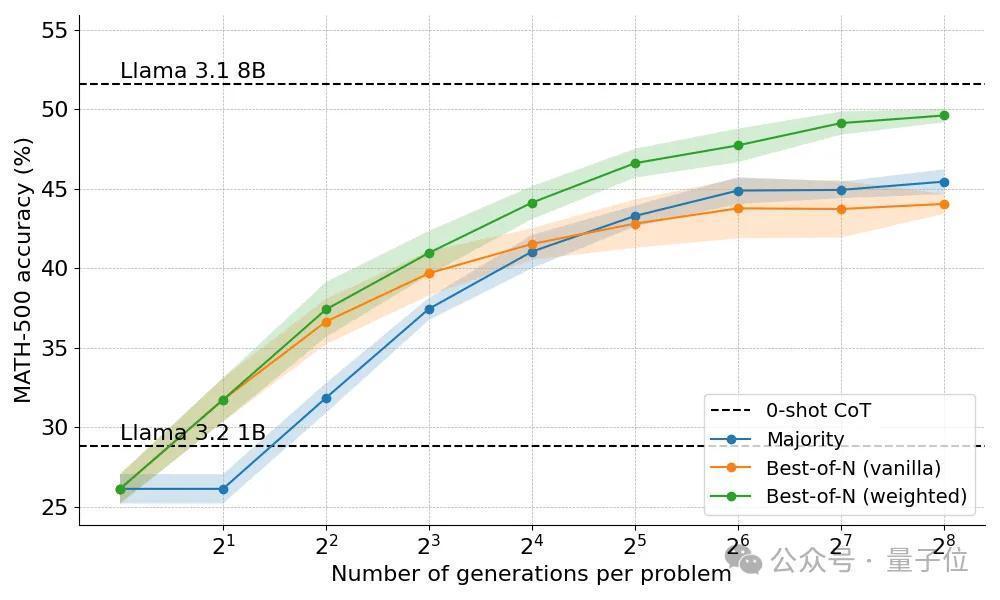
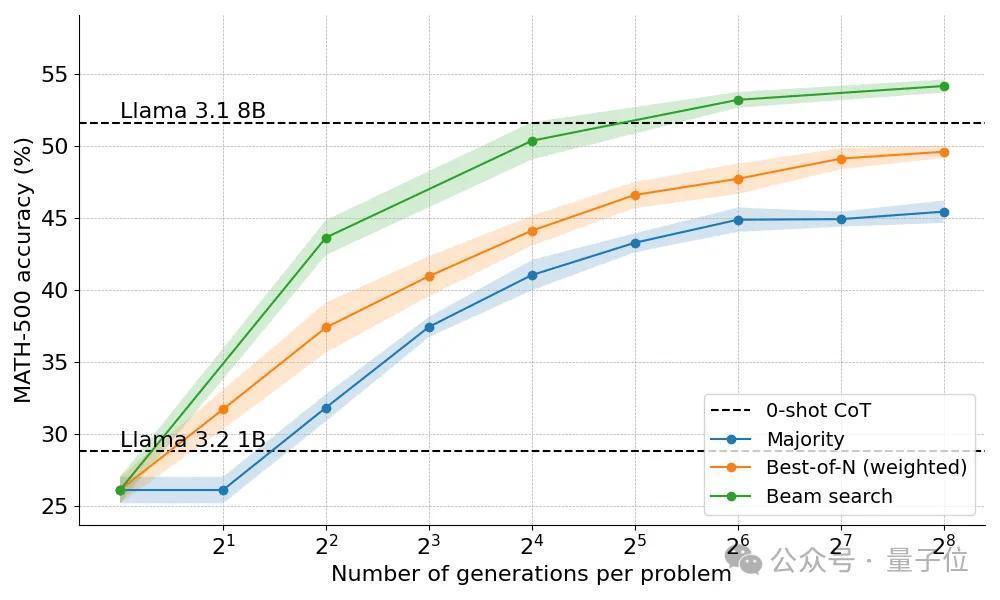
Beam Search政策终于让1B模子进展起初高于8B。
但Beam Search并不是万金油措施,在轻视的问题上进展反而不如Best-of-N。
团队通过检验效果树,发现淌若一个中间才能获取了高分,那么统共这个词树就会垮塌到这一步,影响了后续谜底的各样性。
最终,DVTS措施创新了谜底的各样性,该措施与Beam Search比拟有以下不同之处:
关于给定的Beam宽度(M)和生成数目N,运转Beam集设定为N/M个零丁子树关于每个子树,选拔PRM分数最高的才能生成M个新的下一步,不时选拔分数最高的重叠这个过程,直到生成EOS token后阻隔,或达到最大深度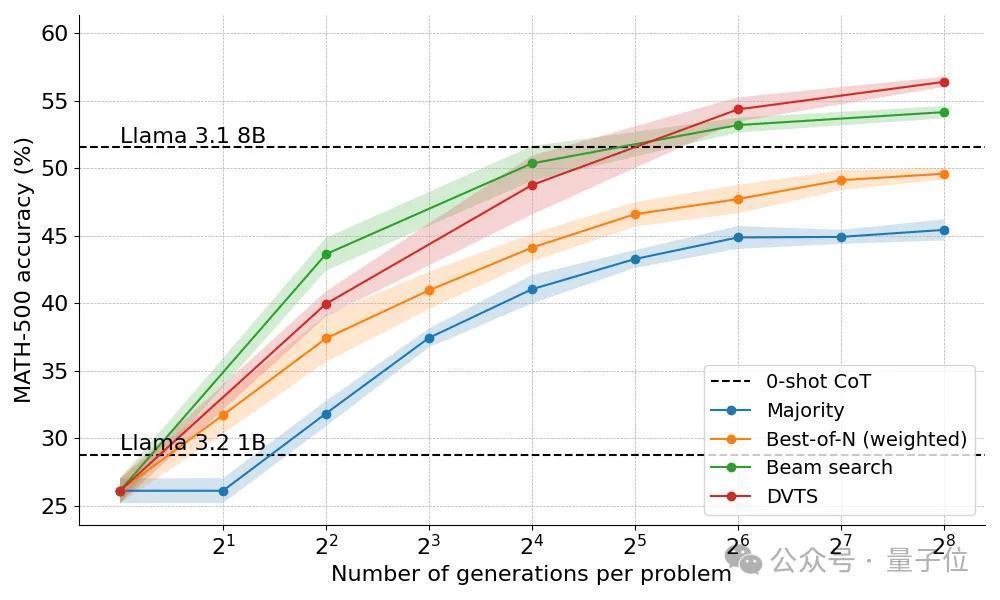
在对问题难度细分后,发现DVTS措施在N比较大时增强了对轻视/中等难度问题的性能。
而Beam Search在N比较小时仍然进展最好。
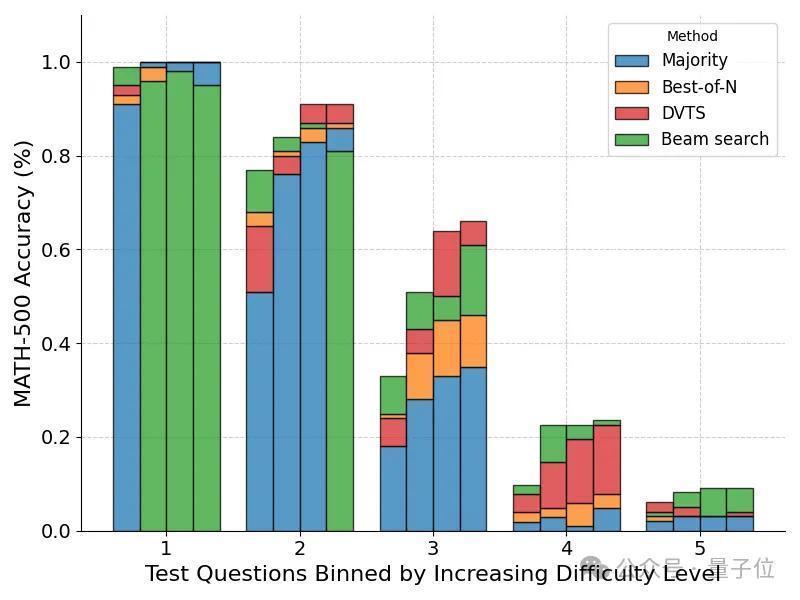
最终基于问题难度动态分派政策的措施不错取得最好收成。
临了团队提议,改日这项工夫还有更多值得探索的方位:
更宏大的考据器,擢升其隆重性和泛化身手至关蹙迫。最终方针是已矣自我考据,现在在施行中仍然难以已矣,需要更邃密的政策。在生成过程中加入明确的中间才能或 “思法” ,通过将结构化推理整合到搜索过程中,不错在复杂任务中获取更好的性能。搜索措施不错用于合成数据,创建高质料的熟习数据集灵通的经由奖励模子现在数目较少,是开源社区不错作念出要紧孝敬的领域现在的措施在数学和代码等领域进展出色,这些问题本色上是可考据的,怎样将这些工夫膨胀到结构性较差或评判圭臬主不雅的任务,照旧一个要紧挑战。驳倒区有网友暗意,这种措施更相宜土产货部署,而不是API调用,因为调用256次3B模子和过程奖励模子,频频会比调用一次70B模子更贵。
也有东说念主建议在Qwen系列模子上尝试,以及指路天工Skywork发布了两个基于Qwen的PRM模子
开源代码:
https://github.com/huggingface/search-and-learn参考联络:
[1]https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute[2]https://x.com/_lewtun/status/1868703456602865880— 完 —
量子位 QbitAI · 头条号签约
关爱咱们,第一时候获知前沿科技动态