AI时期居品司理必须懂得的期间,谈谈Rag的产生原因、基本旨趣与实施旅途
发布日期:2025-03-31 14:35 点击次数:115

在东说念主工智能限制,RAG 期间正成为激动大模子应用的要害。本文将深刻探讨 RAG 期间的旨趣、挑战以及在不同阶段的优化策略,匡助读者全面了解并灵验实施这一期间。若是你对擢升 AI Agent 的性能感酷爱酷爱,不妨络续阅读。
在《大佬们都在温顺的 AI Agent,到底是什么?用 5W1H 分析框架拆解 AI Agent(上篇)》中,风叔提到要收场考究的 AI Agent 性能,RAG 期间的使用至关紧迫,今天咱们就来重心谈一谈 RAG。
关于 Rag 系统的举座框架,风叔作念了梳理。想提前了解全部内容的同学,不错温顺 GZH “风叔云”,回复要害词“ Rag 框架”,赢得齐备内容。
一、什么是 Rag?
RAG,Retrieval-Augmented Generation,华文名检索增强生成,是 AI 限制特别紧迫的一种期间决议。其中枢作用是给 LLM 大模子外挂有意的学问库,率领大模子生成更准确的输出。
为什么要给 LLM 大模子外挂学问库呢?因为固然大模子的能力越来越强劲,但其内在的症结也特别昭彰。
第一,存在幻觉问题。LLM 大模子的底层旨趣是基于数学概率进行斟酌,其模子输出骨子上是一种概率斟酌的驱散。是以 LLM 大模子偶然候会出现心直口快,或者生成一些不足为法的谜底,在大模子并不擅长的限制,幻觉问题会愈加严重。使用者要区别幻觉问题口舌常难得的,除非使用者自己就具备了相应限制的学问,但这里就会存在矛盾,已经具备关系学问的东说念主是不会摄取大模子生成的谜底的。
第二,穷乏对生成驱散的可证据性。LLM 大模子自己便是一个黑盒,这个模子使用了什么数据进行考试,对都策略是怎样样的,使用者都无从得知。是以关于大模子生成的谜底,愈加难以跟踪溯源。
第三,穷乏对专科限制学问的意会。LLM 大模子学问的赢得严重依赖考试数据集的广度,但当今市面上大多数的数据考试集都开端于采集公开数据,关于企业里面数据、特定限制或高度专科化的学问,大模子无从学习。因此大模子的进展更像是一个合格的通才,关联词在一些专考场景,比如企业里面的业务流,一个合格的通才是无法使用的,需要垄断企业的专属数据进行喂养和考试,打造为优秀的专才。
第四,数据的安全性。这是对上头第三点的延长,莫得企业惬心承担数据裸露的风险,将自身的私域数据上传第三方平台进行考试。因此,彻底依赖通用大模子自身能力的应用决议,在企业场景下是行欠亨的。
第五,学问的时效性不及。大模子的内在结构会被固化在其被考试完成的那一刻,关联词当你研究大模子一些最新发生的事情,则难以给出谜底。
为了克服这些问题,第一种样式是微调,即 Finetune。关联词由于生成模子依赖于内在学问,也便是种种参数的权重,即使作念了微调,模子如故无法开脱幻觉问题。此外皮试验场景中,许多新的信息、数据、计策物换星移都在产生,除非对模子进行高频的微调,不然模子的考试速率永恒赶不上外部信息更新的速率,而高频微调的本钱就太高了,
在 2020 年,Meta AI 的研究东说念主员提议了检索增强生成(RAG)的标准,为 LLM 大模子提供了一种与外部信息高效互动的惩处决议。其主要作用肖似于搜索引擎,找到用户发问最关系的学问或者是关系的对话历史,并说合原始发问,创造信息丰富的 prompt,率领 LLM 大模子生成更准确的输出。
这便是 Rag 期间产生的配景和原因。
二、Rag 期间的基本旨趣
RAG 可分为 5 个基本历程:学问文档的准备、镶嵌模子、存入向量数据库、查询检索和坐褥回答。
现实场景中,咱们靠近的学问源可能包括多种风光,如 Word 文档、TXT 文献、CSV 数据表、Excel 表格,致使图片和视频。因此需要使用有意的文档加载器(举例 PDF 索求器)或多模态模子(如 OCR 期间),将这些丰富的学问源颐养为谎言语模子可意会的纯文本数据,然后开启 RAG 的五个中枢技艺。
第一步,文档切片 / 分块:在企业级应用场景中,文档尺寸可能特别大,因此需要将长篇文档分割成多个文本块,以便更高效地处理和检索信息。分块的样式有许多种,比如按段落、按内甘心者其他特别结构。同期,需要禁绝分块的尺寸,若是分块太小,固然查询更精确,但调回时刻更长;若是分块太大,则会影响查询精确度。
第二步,镶嵌模子:镶嵌模子的中枢任务是将文本颐养为向量体式,这么咱们就能通过简便的计划向量之间的互异性,来识别语义上相通的句子。
第三步,存入向量数据库:将文档切片和镶嵌模子的驱散存储参加向量数据库。向量数据库的主要上风在于,它能够凭证数据的向量接近度或相通度,快速、精确地定位和检索数据,收场许多传统数据库无法收场的功能,比如凭证旋律和节律搜索出特定的歌曲、在电影中搜索扬弃的片断、在文档中找出意图左近的段落等等。
第四步,用户查询检索:用户的问题会被输入到镶嵌模子中进行向量化处理,然后系统会在向量数据库中搜索与该问题向量语义上相通的学问文本或历史对话纪录并复返,这便是检索增强。
第五步,生成问答:最终将用户发问和上一步中检索到的信息说合,构建出一个指示模版,输入到谎言语模子中,由大模子生成最终的驱散并复返。
Rag 期间仍是问世,就取得了特别无为的使用,成为 AI 大模子居品落地中必弗成少的一环。凭证具体的使用场景,不错分为以下几类。
通用问答系统:RAG 不错凭证检索到的关系信息生成准确的谜底,匡助职工更快地赢得所需信息,提高决策后果,比如搭建企业里面学问库、公司规矩轨制查询、新职工入职培训、公司合同辛苦解读和查询等。
智能客服系统:RAG 不错说合居品辛苦学问库、聊天纪录、用户反馈等数据,自动为用户提供更精确的回答,已经有特别多的初创公司遴聘请 RAG 期间构建新一代的智能客服系统。
智能数据分析:RAG 不错说合外部数据源,如数据库、API、文献等,为用户提供更方便的数据分析做事。传统企业的数据分析主要靠 BI 分析师,每天都需要写大都的 SQL 语句进行查询,而在 RAG 的复古下,企业的每个职工都能以天然对话的样式赢得数据。比如门店店长顺利用语音对话,“请帮我找出上周销量名次前 10,但本周销量下滑最快的品类”,系统即可顺利给出回报。
自动化文档处理:企业还不错垄断 RAG 和 LLM 大模子自动化文档处理历程,举例自动生成合同、撰写周报、转头会议纪要等,勤俭时刻和东说念主力本钱。
三、Rag 实施旅途
Rag 期间固然相对比拟容易初学,关联词要部署到坐褥环境而且对外提供褂讪的做事,如故有许多路要走的,尤其是其历程的各个枢纽都有特别多的优化空间。
从优化的地方来看,主要包括四个方面,学问分块与索引优化、用户 query 改写优化、数据调回优化和内容生成优化。天然,“罗马不是一天建成的”,Rag 关系风光的实施也需要分阶段冉冉进行迭代和优化,风叔建议不错按照以下三个阶段来实施。
第一阶段,可运行,即系统能跑通举座历程
1)学问分块与索引
在 RAG 系统中,文档需要分割成多个文本块再进行向量镶嵌。在不探究大模子输入长度限度和本钱问题情况下,其主见是在保抓语义上的连贯性的同期,尽可能减少镶嵌内容中的噪声,从而更灵验地找到与用户查询最关系的文档部分。
若是分块太大,可能包含太多不关系的信息,从而镌汰了检索的准确性。相背,分块太小可能会丢失必要的高下文信息,导致生成的复兴穷乏连贯性或深度。
第一阶段可先按固定字符拆分学问,并通过配置冗余字符来镌汰句子截断的问题,使一个齐备的句子要么在上文,要么鄙人文。这种样式能尽量幸免在句子中远隔开的问题,且收场本钱最低,特别安妥在业务起步阶段。
2)用户 Query 改写
在 RAG 系统中,用户的查研究题会被飘浮为向量,然后在向量数据库中进行匹配,因此查询的措辞准确度会顺利影响搜索的驱散。在向量空间中,对东说念主类来说看似疏导的两个问题其向量大小并不一定很相通
咱们不错摄取“查询重写”决议,即顺利垄断 LLM 大模子从头表述问题。在进行多轮对话时,用户发问中的某些内容可能会指代上文中的部分信息,不错将历史信息和用户发问一并交给 LLM 大模子进行从头表述。
总体来说,第一阶段不错先顺利使用大模子的意会能力,说合高下文,隆升引户意图。此时不需要作念过多的 Query 改写,以测试大模子意会能力和跑通历程为主。
3)数据调回
第一阶段不错先使用最简便的向量调回样式,找到在语义向量维度最近似的谜底进行调回。这里需要禁绝的是,要找一个和我方业务比拟契合的 embedding 模子和向量数据库。
调回驱散的数目是另一个要害因素,更多的驱散不错提供丰富的预见,有助于系统更好地意会问题的高下文和隐含细节。关联词驱散数目过多可能导致信息过载,镌汰回答准确性并加多系统的时刻和资源本钱。第一阶段咱们不错先把调回数目配置为 10。
4)内容生成
内容生成枢纽更多的是探究用户体验,在第一阶段咱们不错先简便一些,能顺利输出谜底即可。因为数据调回文节只消向量调回,因此这一步不错只将上一步调回文节复返的 top 10 的学问筛选出来,然后提供给大模子生成谜底。
第一阶段的系统可能会存在较多问题,群众会发现生成谜底的关系性和准确度都比拟低。关联词不紧要,这一阶段的首要任务是跑通系统历程,优化的使命咱们放在第二和第三阶段再作念。
第二阶段,可使用,即系统初步达到可上线水平
学问的分块与索引,对最终谜底生成的准确性有特别大的影响,尤其是在处理超长文本的时候,会出现索引玷污问题。
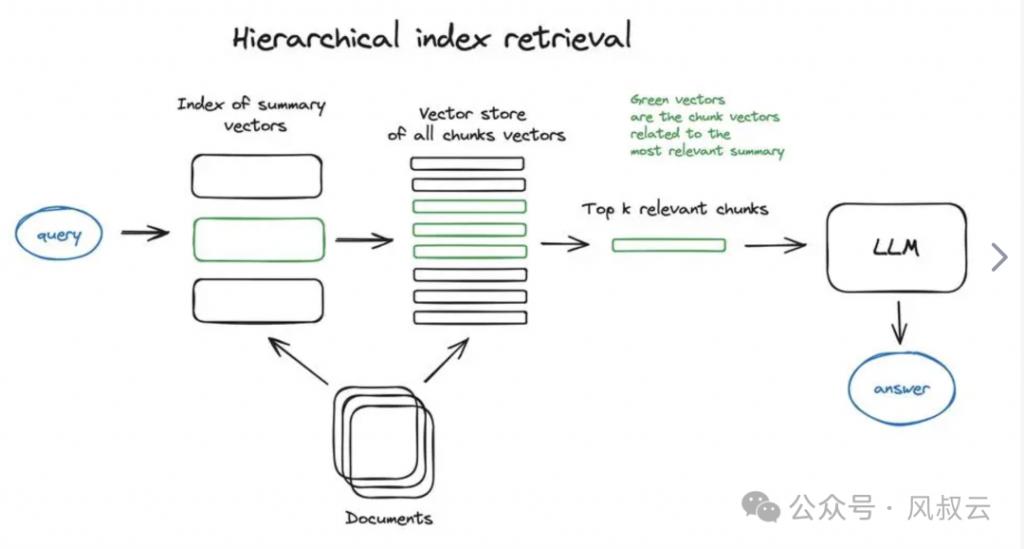
索引玷污是指学问文档的中枢要害词被湮没在大都的无效信息中,比如大都不足轻重的助词、口吻词、或无关信息,导致教育的索引中中枢学问比重少,从而影响生成谜底的质地。针对这个问题,咱们不错摄取三种优化决议,索引降噪、多级索引和 HYDE。
索引降噪:是凭证业务特色,去除索引数据中的无效因素,隆起其中枢学问,从而镌汰杂音的阻挠,保险中枢学问的比重。比如原文档内容是“ How can I download source code from github.com ”,其中枢内容是“ download source code、github ”,其他杂音不错忽略。
多级索引:是指创建两个索引,一个由文档节录构成,另一个由文档块构成,并分两步搜索,领先通过节录过滤掉关系文档,然后只在这个关系组内进行搜索。这种多重索引策略使 RAG 系统能够凭证查询的性质和高下文,遴聘最合适的索引进行数据检索,从而擢升检索质地和反映速率。但为了引入多重索引期间,咱们还需配套加入多级路由机制,比如关于查询“最新发表的 Rag 论文保举”,RAG 系统率先将其路由至论文专题的索引,然后凭证时刻筛选最新的 Rag 关系论文。
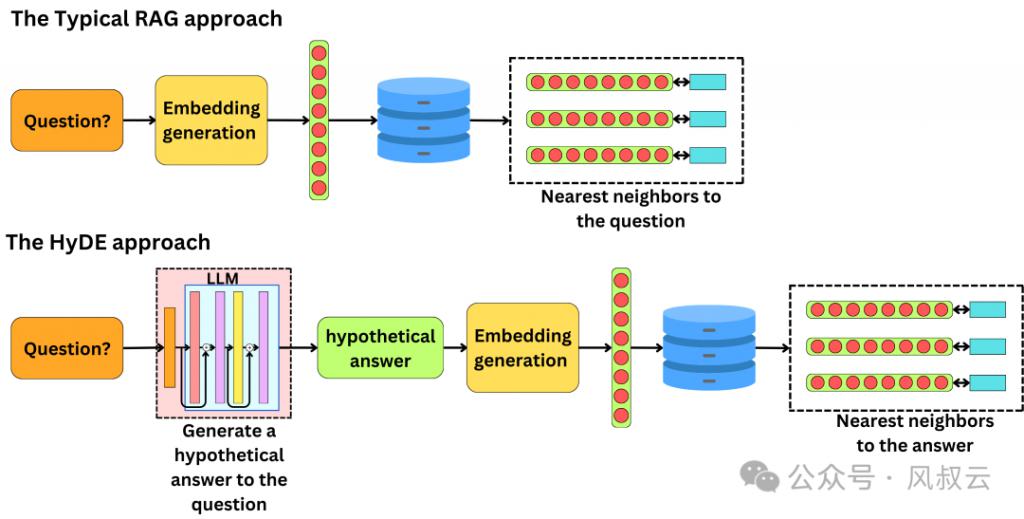
HYDE:全称是 Hypothetical Document Embeddings,用 LLM 生成一个“假定”谜底,将其和问题一说念进行检索。HyDE 的中枢想想是接登第户发问后,先让 LLM 在莫得外部学问的情况下生成一个假定性的回复。然后,将这个假定性回复和原始查询一说念用于向量检索。假定回复可能包含差错信息,但蕴含着 LLM 合计关系的信息和文档模式,有助于在学问库中寻找肖似的文档。
顺利使用原始的用户 query 进行检索,会存在一些问题。比如学问库内的数据无法顺利回答,需要组合多种学问能力找到谜底;此外,波及细节比拟多的问题,大模子络续无法进行高质地的回答。不错使用 Rag-Fusion 进行优化。
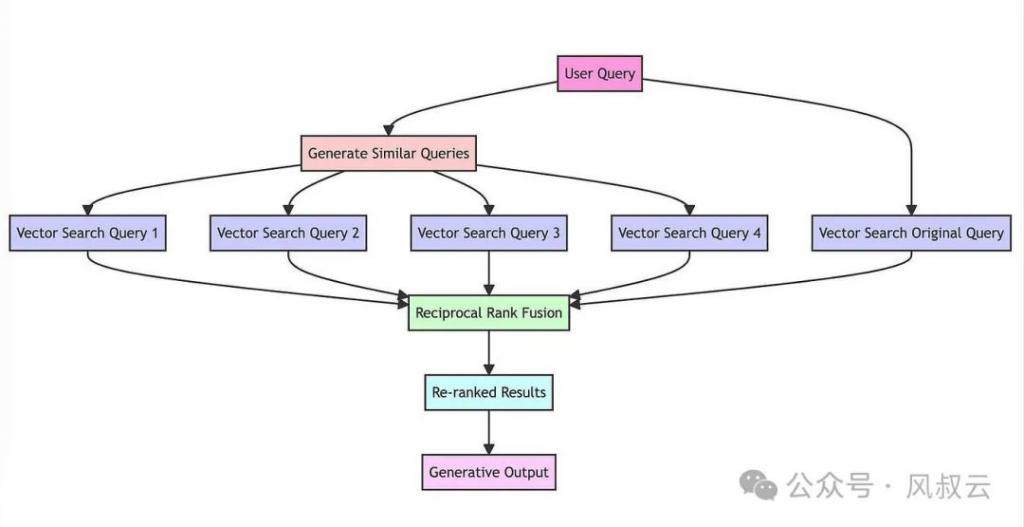
RAG-Fusion:领先对用户的原始 query 进行蔓延,即使用 LLM 模子对用户的驱动查询,进行改写生成多个查询;然后对每个生成的查询进行基于向量的搜索,造成多路搜索调回;接着应用倒数名次和会算法,凭证文档在多个查询中的关系性从头罗列文档,生成最终输出。
在第一阶段,咱们使用了单纯的语义向量作念调回,关联词当文本向量化模子考试不够好时,向量调回的准确率会比拟低,此时需要垄断其他调回样式作为补充。
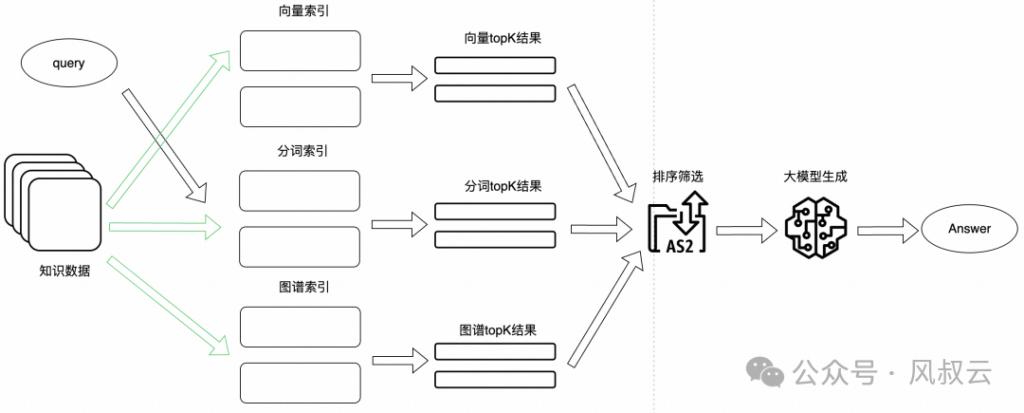
分词调回:一种灵验的稀零搜索算法是最好匹配 25(BM25),它基于统计输入短语中的单词频率,日常出现的单词得分较低,而宝贵的词被视为要害词,得分会较高。咱们不错说合稀零和宽绰搜索得出最终驱散。
多路调回:多路调回的驱散经过模子精排,最终筛选出优质驱散。至于使用几种调回策略,凭证业务而定。
凭证前几个枢纽的优化策略,内容生成枢纽也需要有相应的治疗。
文档合并去重:多路调回可能都会调回归并个驱散,针对这部分数据要去重,不然对大模子输入的 token 数是一种花费;其次,去重后的文档不错凭证数据切分的血统关系,作念文档的合并。
重排模子:重排模子通过对驱动检索驱散进行更深刻的关系性评估和排序,确保最终展示给用户的驱散愈加适合其查询意图。这一过程日常由深度学习模子收场,如 Cohere 模子。这些模子会探究更多的特征,如查询意图、词汇的多重语义、用户的历史步履和高下文信息等。
经过第二阶段的优化,谜底生成的关系性和准确度都会大幅擢升,关联词仍然会有较好像率出现卯分歧榫的情况,咱们还需要对系统作念更进一步的优化。
第三阶段,很好用,即系统回答的准确率达到用户酣畅水平
底下,风叔先容一些更高档的 Rag 优化策略。
固然在第二阶段,咱们通过索引降噪、多级索引、HYDE 等样式,大幅擢升了学问库的准确度,关联词按固定字符切,偶然候会遭受句子含义推敲比拟细腻的片断被切分红了两条数据,导致数据质地比拟差。
这个情况下不错尝试考试有意的语义意会小模子,然后使用试验语义进行句子拆分,使拆分出来的学问片断语义愈加齐备。
另外一种标准是构建元数据,加多内容节录、时刻戳、用户可能提议的问题等附加信息来丰富学问库,而元数据不需要被向量化。此外,咱们还不错添加诸如章节或末节的援用,文本的要害信息、末节标题或要害词等作为元数据,有助于更动学问检索的准确性。
还有一种愈加灵验的样式是教育学问图谱。镶嵌模子固然简便,关联词没法灵验捕捉实体之间的复杂关系和线索结构,是以导致传统 RAG 在靠近复杂查询的时候终点笨重。比如,用户研究“《朝上范畴》这本书的主旨是什么”,传统 Rag 期间是详情回答不出来的。关联词学问图谱期间不错作念到,因为垄断学问图谱对数据集教育索引的时候,会作念索务实体以及实体之间的关系,这么就能构建一种全局性的上风,从而擢升 RAG 的精确度。
关联词,学问图谱固然很强劲,可惜本钱太高了,会大幅擢升 token 使用量,群众需要空洞居品体验和本钱进行评估。
2)用户 query 改写
Step-Back Prompting:若是果原始查询太复杂或复返的信息太无为,咱们不错遴聘生成一个抽象线索更高的“退后”问题,与原始问题一说念用于检索,以加多复返驱散的数目。举例,关于问题“勒布朗詹姆斯在 2005 年至 2010 年在哪些球队?”这个问题因为偶然刻范围的凝视限度,比拟难顺利惩处,不错提议一个后退问题“勒布朗詹姆斯的作事生活是怎样样的?”,从这个回答的调回驱散中再检索上一个问题的谜底。
图谱调回:若是在学问分块枢纽使用了学问图谱,那么咱们就不错顺利用图谱调回,大幅擢升调回准确度。
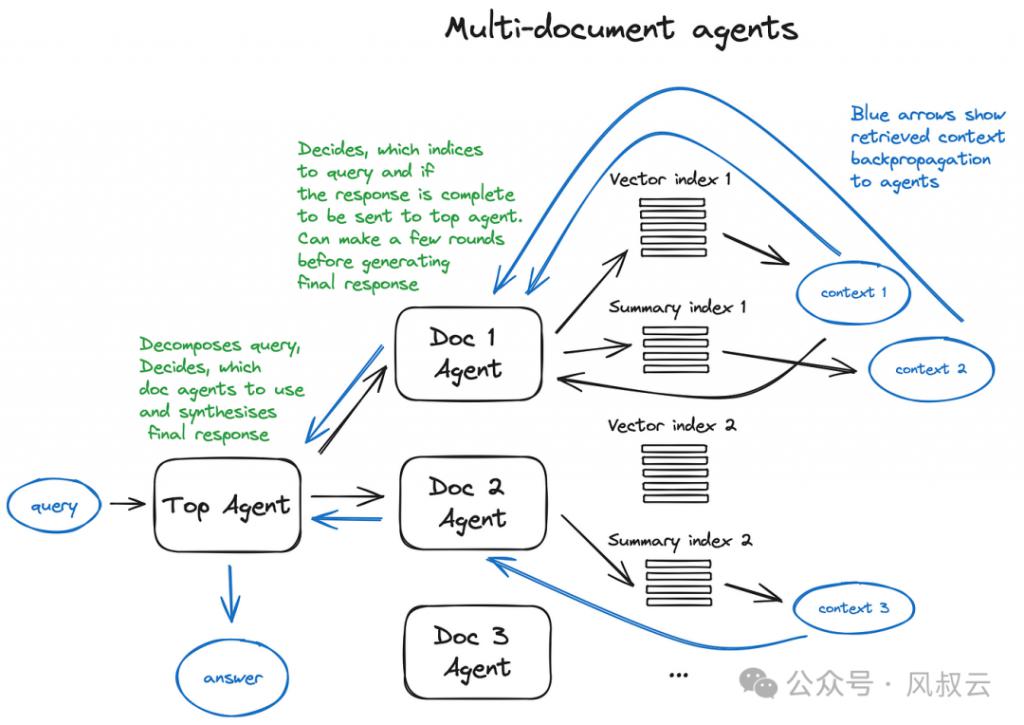
Agentic-rag:RAG 应用退化成一个 Agent 使用的学问器具。咱们不错针对一个文档 / 学问库构建多种不同的 RAG 引擎,比如使用向量索引来去答事实性问题;使用节录索引来去答转头性问题;使用学问图谱索引来去答需要更多关联性的问题等。
在单个文档 / 学问库的多个 RAG 引擎之上配置一个 DocAgent,把 RAG 引擎作为该 Agent 的 tools,并垄断 LLM 的能力由 ToolAgent 在我方“肃穆”的文档内使用这些 tools 来去答问题。终末配置一个总的顶级代理 TopAgent 来管制通盘的低阶 DocAgent,将 DocAgent 看作我方的 tools,仍然垄断 LLM 来计议、合作、实行用户问题的回答决议
Prompt 优化:RAG 系统中的 prompt 应明确指出回答仅基于搜索驱散,不要添加任何其他信息。举例不错配置 prompt:“你是别称智能客服。你的方针是提供准确的信息,并尽可能匡助发问者惩处问题。你应保抓友善,但不要过于啰嗦。请凭证提供的高下文信息,在不探究已有学问的情况下,回答关系查询。” 此外,使用 Few-shot 的标准率领 LLM 如何垄断检索到的学问,亦然擢升 LLM 生成内容质地的灵验标准。
Self-rag:self-rag 通过检索评分(令牌)和反想评分(令牌)来提高质地,主要分为三个技艺:检索、生成和品评。Self-RAG 领先用检索评分来评估用户发问是否需要检索,若是需要检索,LLM 将调用外部检索模块查找关系文档。接着,LLM 分别为每个检索到的学问块生成谜底,然后为每个谜底生成反想评分来评估检索到的文档是否关系,终末将评分高的文档看成最终驱散一并交给 LLM。
四、转头
本篇著作重心先容了 Rag 期间的认识、产生原因、基本旨趣和实施旅途,不错作为 AI 居品司理和研发同学在试验风光中的参考辛苦。
围绕 Rag 关系的各项期间和理念仍然在马上迭代,从大地方来说,风叔比拟看好学问图谱和 AI Agent 在 Rag 系统中的使用。
学问图谱的本钱一定会络续下落,那么一定存在一个临界点,即使用学问图谱带来的对实体和实体关系的意会上风,会远庞杂于对本钱的考量。
关于 AI Agent,其自己和 Rag 亦然相得益彰的关系。Rag 系统为 AI Agent 提供持久回首能力,而 AI Agent 的计议与反想也会为 Rag 系统提供特别好的计议管制和路由能力。
战胜 Rag 会在各个限制的 AI 居品落地过程中,抓续上演紧迫的扮装。
题图来自 Unsplash,基于 CC0 合同。