马斯克用20万张GPU“砸出”地表最强AI?每经记者实测Grok 3:速率称王,数学亮眼,但逻辑念念考不敌DeepSeek R1
发布日期:2025-04-04 07:07 点击次数:70

近日,东谈主工智能初创公司xAI发布了更新版Grok 3大模子,埃隆·马斯克称之为“地球上最机灵的东谈主工智能”。
凭证官方公开的测试为止,Grok 3在包括AIME(评估模子在一系列数学问题上的弘扬)和 GPQA(评估模子在博士级别的物理学、生物学和化学问题上的弘扬)等基准测试中,远超 GPT-4o、Gemini-2 Pro、DeepSeek V3、Claude 3.5 Sonnet 等大模子。
在大模子竞技场 Chatbot Arena(LMSYS)测试中,xAI工程师示意,早期版块的Grok 3赢得了第一的得益,达到了140分,超越了Gemini 2.0 Flash Thinking实验版块、ChatGPT-4o最新版块以及最近大火的DeepSeek R1等等。
联系词,有些用户在体验后却对Grok 3的技能产生了质疑,他们合计Grok 3的技能并莫得马斯克宣称的那么高大。OpenAI应用接头专揽Boris Power则对Grok团队在模子评估中的算作示意失望,指出其存在舞弊和诳骗的动机。Boris Power提到,o3-mini在各项评估中均优于Grok 3。
真相到底若何,马斯克显示了吗?《逐日经济记者》测试发现,Grok 3如实是宇宙顶级模子的水平,但并莫得和其他模子拉开太大差距。唯独拉开差距的是它极快的反映速率。
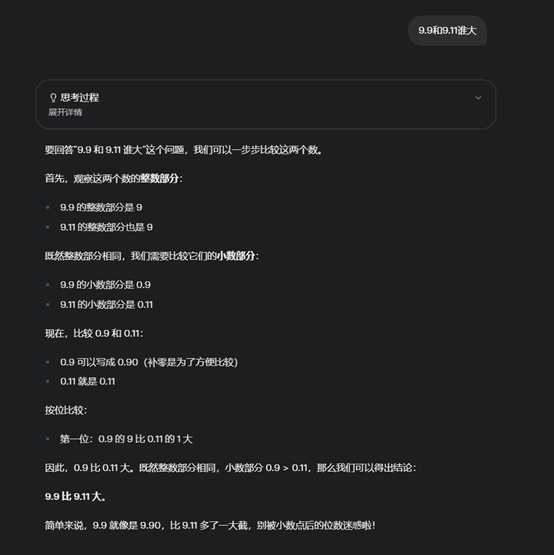
9.9和9.11谁大,Grok 3平缓拿下Grok 3是由马斯克旗下的东谈主工智能公司xAI发布的最新一代AI模子。马斯克在发布会上称其为“地球上最机灵的东谈主工智能”,并示意Grok 3的技能比前代家具Grok 2杰出一个数目级,具备更强的推理、筹算和符合技能。
在新闻发布会上,马斯克宣称Grok 3在数学、科学和编程等基准测试中弘扬出色,超越了谷歌的Gemini、DeepSeek的V3模子、Anthropic的Claude和OpenAI的GPT-4o等竞争敌手。
Grok 3在发布后仅48小时内,xAI通知将其免费通达给扫数效户,直至工作器负载达到极限。当今用户每天不错体验十条“念念考时势”Grok3,及不限量免费普通Grok 3。
《逐日经济新闻》记者在Grok 3发布后也亲身进行了测试,望望Grok3真有马斯克宣传的那么是非吗?
最初,从最经典的基础问题开动:9.9和9.11谁大?
Grok 3
这个问题毫无难度,Grok 3平缓拿下。
逻辑念念考和笔墨领悟技能:Grok 3不如DeepSeek R1马斯克发布会上显示的小数是,Grok 3“念念考模子”下的逻辑推理技能,他宣称,Grok 3 (Think) 学会了创新其束缚问题的计谋,通过回溯改革造作,简化门径,并讹诈其在预教师时期赢得的学问。就像东谈主类在束缚复杂问题时相同,Grok 3 (Think) 不错耗尽几秒钟到几分钟的时辰进行推理,泛泛会磋议多种设施,考据我方的束缚决策,并评估若何精准悠闲问题的条目。
每经记者用弱智吧的问题来考研一下它的逻辑是不是真是过关。
(编者注:“弱智吧”是百度贴吧的一个子论坛。在这个论坛中,用户频频发布包含双关语、多义词、因果畸形和洽音词等具有挑战性的内容,好多内容联想有逻辑陷坑,即使对东谈主类来说也颇具挑战。)
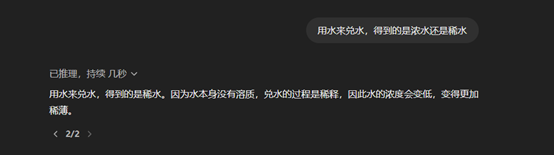
第一个问题:用水来兑水,得到的是浓水照旧稀水?
Grok 3
Grok3得手答对了问题,况兼还指出了这是一个笔墨游戏。而OpenAI的o1就在这谈题上败下了阵来,合计水兑水后得到的是稀水。
OpenAI o1
天然除了o1其他大模子诸如Gemini和R1齐答对了这谈问题。是以这并不及以讲解Grok的推理时势等于第一的水平,还得加浩劫度。
下一题:将来的某天,李同学在实验室制作秘籍材料时,随机发推行验室的老鼠在空中飞,分析发现,是因为老鼠不留心吃了秘籍材料。第二天,李同学又发推行验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发推行验室的老鹰也在空中飞,你合计原因是什么?
Grok 3
很可惜,这谈题Grok 3莫得答对,它在念念维链内部还是料到了老鹰自己就会飞的可能性,可是莫得在临了的输出为止里体现出来。
Grok 3念念考历程
其他大模子里唯有DeepSeek R1得手答对了问题,且磋议了两种情况。
DeepSeek R1
之后,每经记者还进行了屡次类似弱智吧问题测试,发现Grok 3的对中语的领悟和逻辑推理技能如实显着高于其他海外模子,但照旧不如DeepSeek的R1模子。
数学技能:Grok 3最佳,但未拉开显着差距既然逻辑念念考无法夺魁,那么在基准测试里的分最高的数学形势,Grok 3能不行扳回一城呢?
题目如下:
三个东谈主打台球,两东谈主对局一东谈主不雅战,输的东谈主下场换不雅战的东谈主上场,如斯走动,最终,A输了6局,B输了8局,C输了10局,问各赢些许局?
这谈题唯有Grok3和OpenAI的o1答对。不外,Grok 3只用了1分15秒就得出了谜底,O1使用了2分53秒。
Grok 3
再进一步加浩劫度望望能不行分出凹凸。底下是统共群论问题:有几个阶为147的非同构群。
在这个问题上,Grok 3天然答对了具体的数目6个,可是中间的具体群却错了一个。而其他模子只找到了5个正确的非同构群。这意味着,在数学技能方面,Grok 3如实是最佳,可是好得有限,并莫得与其他同品级模子拉开显赫差距。
Grok 3
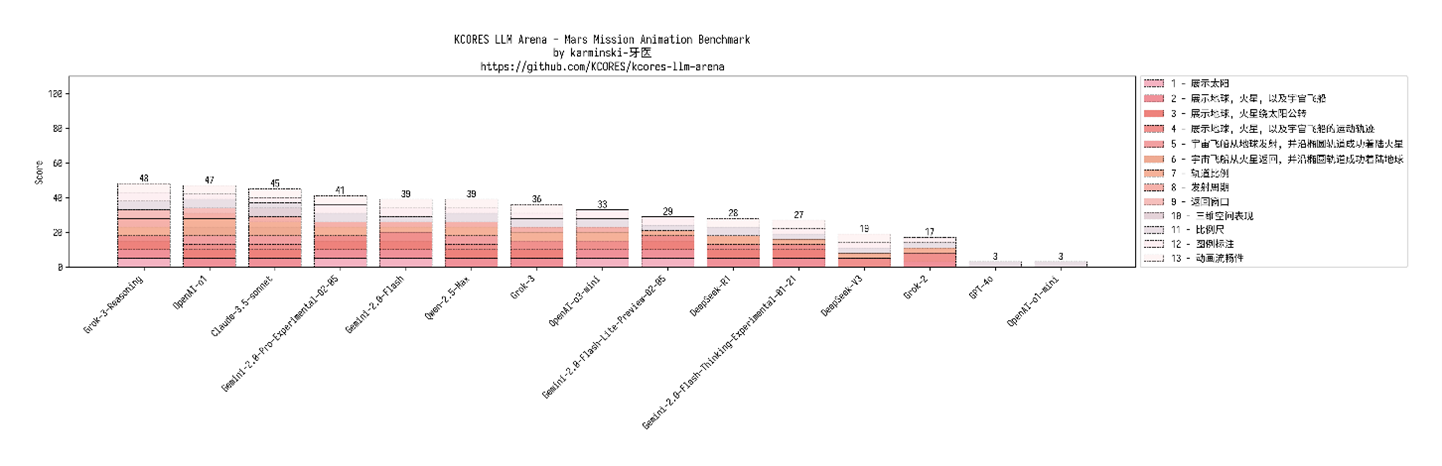
编程技能:Grok 3险胜o1针对编程技能,《逐日经济新闻》记者借用了Kcores聚合首创东谈主karminski-牙医的测评为止。
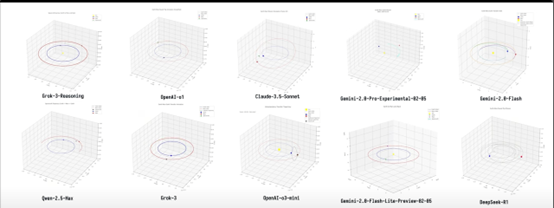
karminski-牙医复现了马斯克在发布会上关于火星辐射谋略的代码模拟,并测试了多个模子进行相比。
图片开头:karminski-牙医
在此次测试中,弘扬最佳的是Grok 3的推理模子(念念考时势),天然在临了着陆时,动画火箭莫得与火星类似,但轨谈需求筹算得很好。可是他持久莫得复现出马斯克在发布会时所展现的那么完整的轨谈筹算和动画。Grok 3临了玄虚得分排在了第别称,再之后是OpenAI的o1,两者的玄虚得分差距不大。
图片开头:karminski-牙医
联接扫数测试来看,Grok 3如实是宇宙顶尖的AI模子,不愧于20万张GPU的身价。可是,骨子测试为止并莫得马斯克在发布会上展示得那么夸张,马斯克所说的宇宙上最“机灵”的模子,可能还值得商榷。
在实测中,《逐日经济新闻》记者发现,Grok 3模子技能并莫得像基准测试得分那样远远甩开敌手一大截,唯独甩开竞争敌手的小数是它的反映速率,它得出为止的速率相较于其他同品级的大模子来说是最快的,况兼远超敌手。
逐日经济新闻