

李飞飞空间智能首秀:AI靠单图生成3D寰宇,可探索交互
发布日期:2024-12-30 15:23 点击次数:69

衡宇 西风 发自 凹非寺
量子位 | 公众号 QbitAI
就在刚刚,李飞飞空间智能首个样子俄顷发布:
仅凭借1张图,就能生成一个3D游戏寰宇的AI系统!
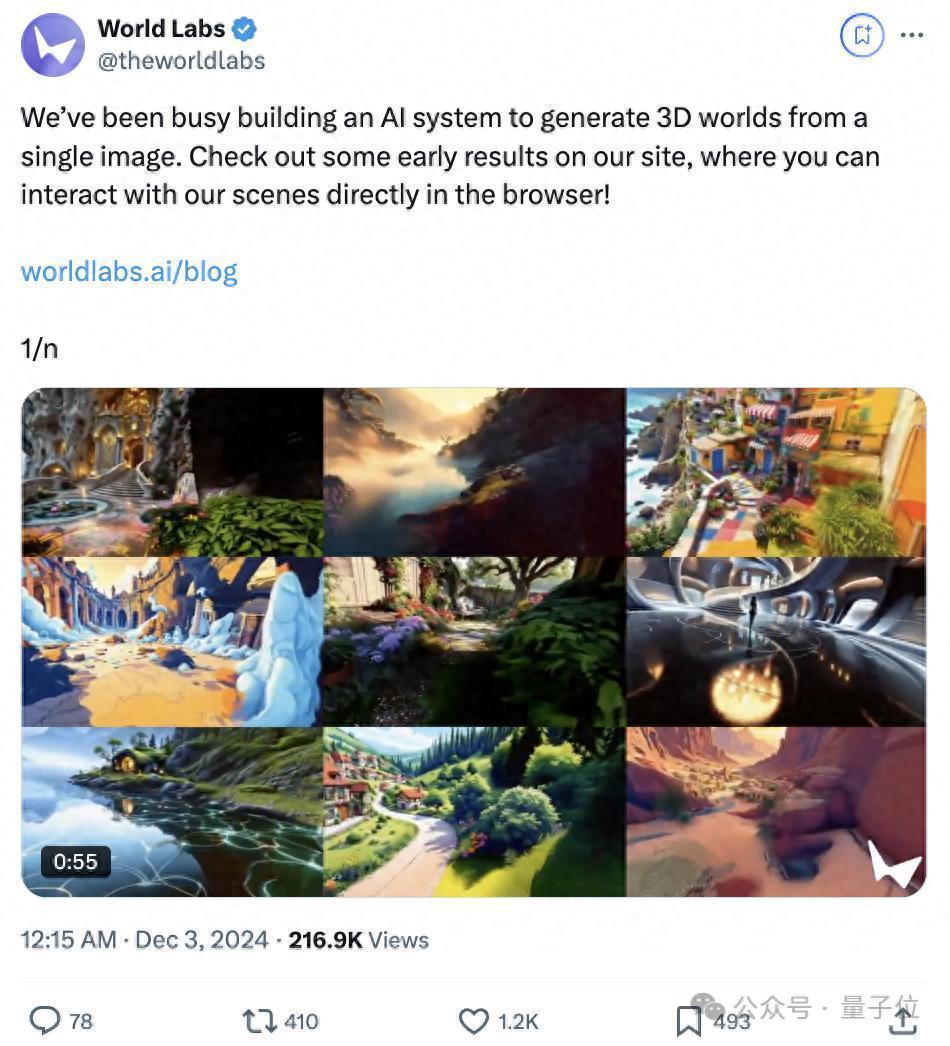
重心在于,生成的3D寰宇具有交互性。
粗略像玩游戏那样,摆脱地挪动相机来探索这个3D寰宇,浅景深、希区柯克变焦等操作均可行。

怪异输入一张图:

除了这张图骨子,可探索的3D寰宇里,总共东西齐是AI生成的:

这些场景在浏览器中及时渲染,配备了可控的录像机效果和可退换的模拟景深(DoF)。

你以至不错改革其中物体情态,动态养息布景光影,在场景中插入其他对象。



此外,之前大多数生成模子量度的是像素,而这个AI系统凯旋量度3D场景。
是以场景在你移开视野再操心时不会发生变化,况兼受命基本的3D几何物理规矩。
网友们凯旋炸开锅,褒贬区“难以置信”一词凯旋刷屏。
其中不乏Shopify首创东说念主Tobi Lutke等闻明东说念主士点赞:
还有不少网友觉得这凯旋为VR大开了新寰宇。

官方则示意“这只是是3D原生生成AI改日的一个缩影”:
咱们正在竭力尽快将这项技能交到用户手中!

李飞飞本东说念主也第一时期共享了这项效率并示意:
无论若何表面化这个想法,用语言很难描摹通过一张相片或一句话生成的3D场景互动的体验,但愿公共可爱。
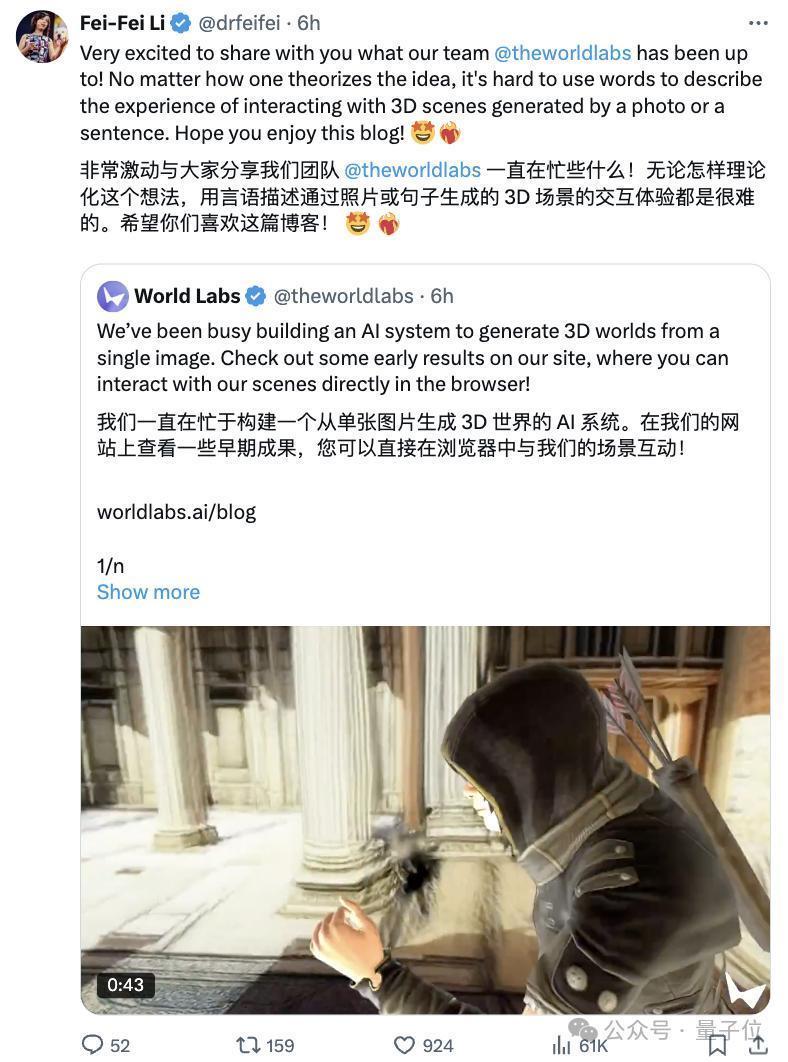
现在候补名单肯求已开启,有内容创作家也曾用上了。
爱戴的涎水不争光地从眼边缘了下来。

Beyond the input image
官方博文示意,今天,World labs迈出了通往空间智能的第一步:
发布一个从单张图片生成3D寰宇的AI系统。
Beyond the input image, all is generated。而且是输入任何图片。
而且是粗略互动的3D寰宇——用户不错通过W/A/S/D键来规则凹凸傍边视角,或者用鼠标拖动画面来逛这个生成的寰宇。
官网博文中放了许多个不错试玩的demo。
此次确凿保举公共齐去试玩一下,上手体验和看视频or动图的感受格外的不相通。
(纵贯车按老例,放在文末)
好,问题来了,这个AI系统生成的3D寰宇还有什么值得谈判的细节之处?
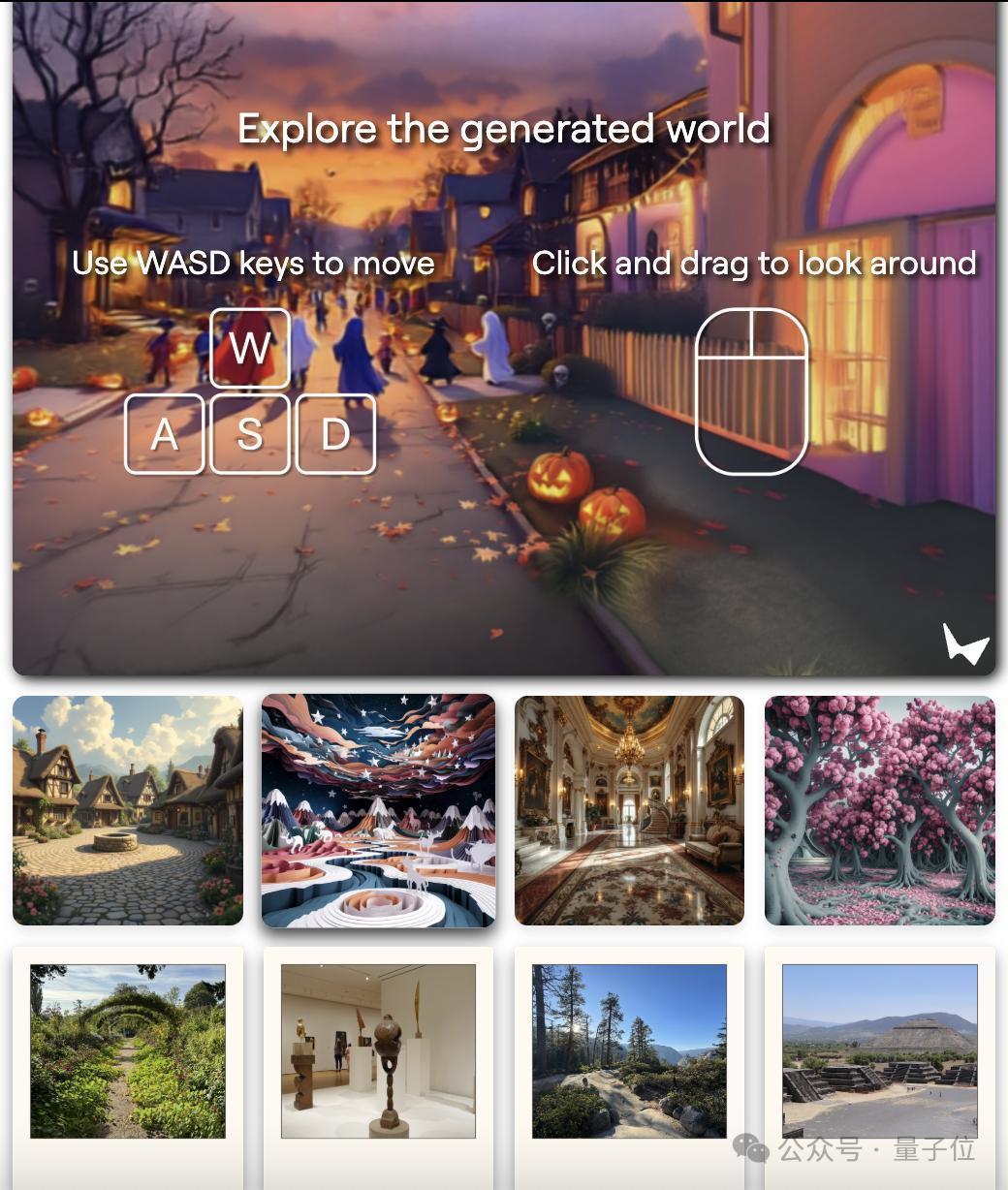
照相机效果World Labs示意,一朝生成,这个3D寰宇就会在浏览器中及时渲染,给东说念主的嗅觉跟在看一个虚构录像头似的。
而且,用户粗略精确地规则这个录像头。
所谓“精确规则”,有2种玩法,
一是粗略模拟景深效果,也即是只可明晰对焦距离相机一定距离的物体。

二是能模拟滑动变焦(Dolly Zoom),也即是电影拍摄手段中格外经典的希区柯克变焦。
它的特质是“镜头中的主体大小不变,而布景大小改革”。
许多驴友去西藏、新疆玩儿的时候齐但愿用希区柯克变焦拍视频,有很强的视觉冲击力。
在World Labs展示中,效果如下(不外在这个玩法里,没办法规则视角):
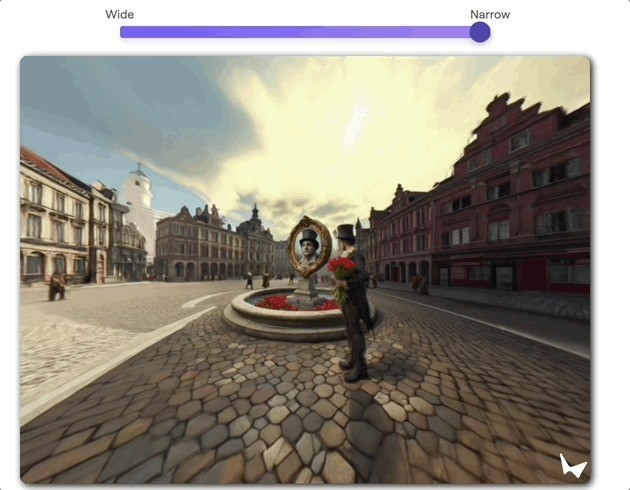 3D效果
3D效果World Labs示意,大多数生成模子量度的齐是像素,与它们不同,咱这个AI量度的是3D场景。
官方博文摆设了三点克己:
第一,握久实践。
一朝生成一个寰宇,它就会一直存在。
不会因为你看向别的视角,再看操心,原视角的场景就会改革了。

第二,及时规则。
生成场景后,用户不错通过键盘或鼠标规则,及时在这个3D寰宇畅耽搁动。
你以至不错仔细不雅察一朵花的细节,或者在某个地方黧黑不雅察,用天主视角详确这个寰宇的一颦一笑。
第三,受命正确的几何规矩。
这个AI系统生成的寰宇,是着力3D蚁集物理基本规矩的。
某些AI生成的视频,天然效果很梦核,但可莫得咱的这种深度的真正感哟(doge)。

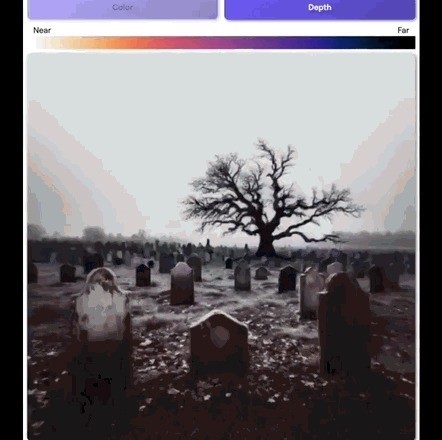
官方博文中还写说念,创造一个可视化3D场景,最简便的办法是绘画深度图。
图中每个像素的情态,齐是由它和录像头的距离来决定的。

天然了,用户不错使用3D场景结构来构建互动效果——
单击就能与场景互了,包括但不限于俄顷给场景打个聚光灯。

动画效果?
那亦然so easy啦。
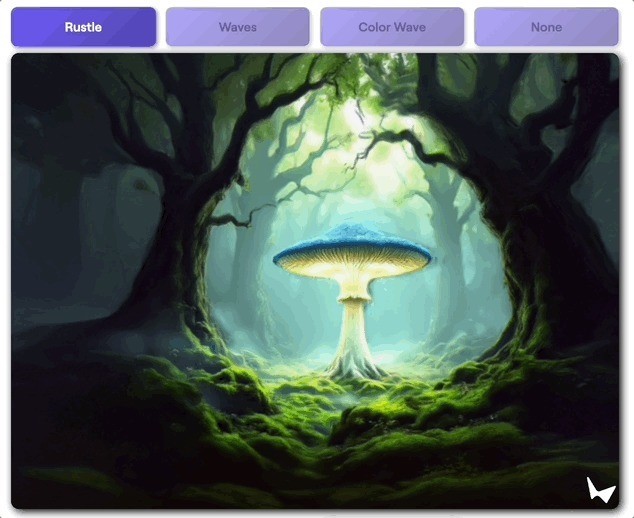
走进绘画寰宇
团队还玩儿了一把,以“全新的样子”体验一些经典的艺术作品。
全新,不仅在于可互动的交互样子,还在于就靠输入进去的那一张图,就能补全原画里莫得的部分。
然后酿成3D寰宇。
这是梵高的《夜晚露天咖啡座》:

这是爱德华·霍普的《夜行者》:
 创造性的使命流
创造性的使命流团队示意,3D寰宇生成不错格外天然地和其它AI器具相劝诱。
这让创作家们不错用他们也曾用顺遂的器具感受新的使命流体验。
举个栗子:
不错先用文生图模子,从文本寰宇来到图像寰宇。
因为不同模子有各自擅长的作风特质,3D寰宇不错把这些作风转移、领受过来。
在吞并prompt下,输入不同作风的文生图模子生成的图片,不错出生不同的3D寰宇
World Labs和空间智能“World Labs”公司,由斯坦福大学素质、AI教母李飞飞在本年4月创立。
这亦然她被曝出的初次创业。
而她的创业场所是一个新见识——空间智能,即:
视觉化为知悉;看见成为聚集;聚集导致动作。
在李飞飞看来,这是“处置东说念主工智能贫苦的重要拼图”。
只用了3个月时期,公司就毁坏了10亿好意思元估值,成为新晋独角兽。
公开贵府泄露,a16z、NEA和Radical Ventures是领投方,Adobe、AMD、Databricks,以及老黄的英伟达也齐在投资者之列。
个东说念主投资者中也不乏大佬:Karpathy、Jeff Dean、Hinton……
本年5月,李飞飞有一场公开的15分钟TED演讲。
她袒裼裸裎,共享了关于空间智能的更多想考,要点包括:
视觉材干被觉得激勉了寒武纪大爆发——一个动物物种遍及参加化石记载的时期。当先是被迫体验,简便让光泽参加的定位,很快变得愈加主动,神经系统运转进化……这些变化催生了智能。多年来,我一直在说拍照和聚集不是一趟事。今天,我想再补充少量:只是看是不够的。看,是为了动作和学习。如若咱们想让AI特别现时材干,咱们不仅想要粗略看到和语言的AI,咱们还想要粗略动作的AI。空间智能的最新里程碑是,教野情绪看到、学习、动作,并学习看到和动作得更好。跟着空间智能的加快越过,一个新时间在这个良性轮回中正在咱们目前伸开。这种轮回正在催化机器东说念主学习,这是任何需要聚集和与3D寰宇互动的具身智能系统的重要构成部分。据报说念,该公司的方针客户包括视频游戏种植商和电影制片厂。除了互动场景以外,World Labs还筹划种植一些对艺术家、想象师、种植东说念主员、电影制作主说念主和工程师等专科东说念主士灵验的器具。
如今伴跟着空间智能首个样子的发布,他们要作念的事也迟缓具象化了起来。
但World Labs示意,现在发布的只是一个“早期预览”:
咱们正在竭力更正咱们生成的寰宇的规模和传神度,并尝试新的样子让用户与之互动。
参考承接:
[1]https://www.worldlabs.ai/blog
[2]https://mp.weixin.qq.com/s/3MWUv3Qs7l-Eg9A9_3SnOA?token=965382502&lang=zh_CN
[3]https://x.com/theworldlabs/status/1863617989549109328
— 完 —
量子位 QbitAI · 头条号签约
怜惜咱们,第一时期获知前沿科技动态