

能想考会搜索的国产大模子,全网疯测的 DeepSeek 牛在哪?
发布日期:2025-03-08 15:07 点击次数:178

IT之家的家友们,蛇年祯祥!
在这个农历新年期间,科技界却并不坦然...
距离 OpenAI 发布由 GPT-3.5 模子驱动的 ChatGPT 聊天机器东谈主,如故往常了两年多的时期。
在这两年间,岂论是微软、谷歌这么的科技巨头,如故如棋布星陈般出现的初创企业,王人在 AI 大模子领域,插足了多半的资源。
算力缓缓扩张,大模子的熟谙及推理资本也相同水长船高。
OpenAI 客岁推出的 ChatGPT Pro 会员,价钱如故来到了每月 200 好意思元。
“屠龙者终成恶龙”,每月 20 好意思元的 ChatGPT Plus 会员,包含的 o1 模子使用次数,不错说只是只够“玩一玩”,很难的确独揽于我方的使命之中。
若是异日资本进一步上升,难谈 AI 的异日,是每月 2000 好意思元的“ChatGPT Pro Max 会员”吗?
可是,一家来自杭州的“小公司” DeepSeek,却给总共 AI 行业带来了新想路,这两天不错说是火遍了全网。IT之家这就来跟公共总共望望是怎样回事。
01. 用起来怎样样?客岁年底,DeepSeek-V3 模子发布,其多项评测收成稀奇了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模子,并在性能上和闭源模子 GPT-4o 以及 Claude-3.5-Sonnet 不分昆仲。
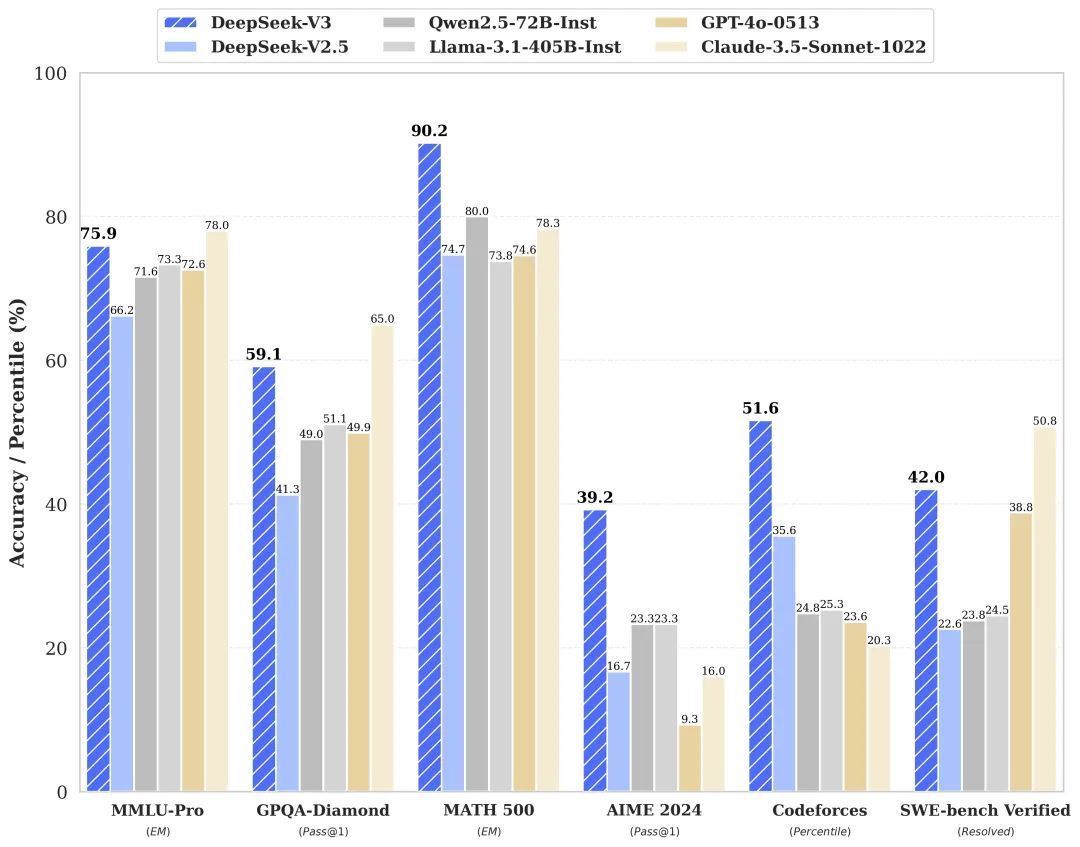
看成一款开源的 MoE 羼杂大师模子,DeepSeek-V3 那时获取了业内东谈主士不少的眷注,但是还并莫得“出圈”。
不外,在 DeepSeek 官方的手机独揽 1 月上旬上线之前,如故有一些盗窟 App 准备凑热度了。

而 1 月 20 日发布的推理模子 DeepSeek-R1,则在性能上兑现了对 OpenAI-o1 郑再版的对标。
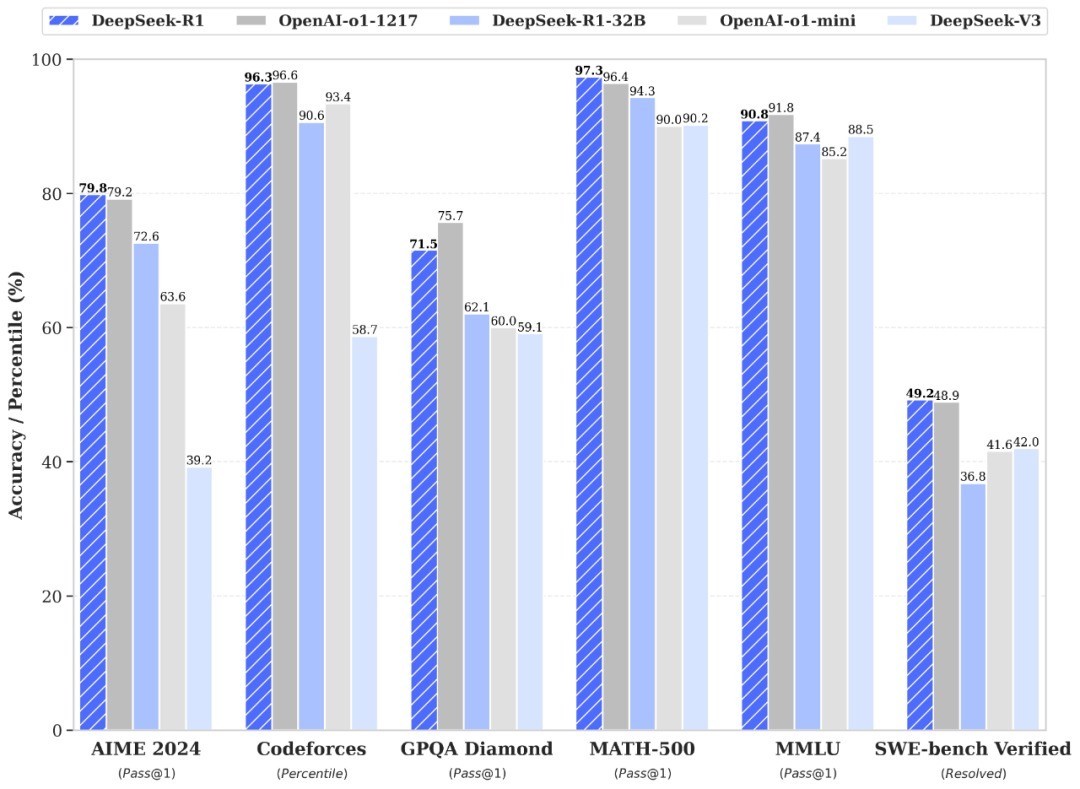
此外,DeepSeek 也并莫得藏着掖着,同期公开了 DeepSeek-R1 的熟谙期间,况兼开源了模子权重。
而且对咱们庸碌用户来说,DeepSeek-R1 径直在其官网免费绽开使用。
而且,DeepSeek-R1 还不错联网搜索信息,加多了不少使用上的活泼性。
要知谈,客岁 10 月 31 号上线的 ChatGPT Search 搜索功能当今还不复旧与 ChatGPT o1 模子协同使用,咱们只可退而求其次聘任 4o 模子。

此外,看成一款接纳 CoT 想维链期间的推理模子,DeepSeek-R1 径直把其想考历程长远给用户,这少许令咱们不错直不雅感受到当今大模子期间的实力。

在海表里全网爆火的同期,DeepSeek 也承受了相等大的压力,信服咱们不少家友王人对底下这句话相等熟悉。

除了多量用户的涌入,DeepSeek 致使还承受了大范围的坏心报复。

要知谈,即即是 ChatGPT,也陆续出现宿机事件,这方面也但愿公共不错“领路万岁”。

除了 671B 参数的竣工模子,DeepSeek 还蒸馏了好几款小模子,32B 和 70B 模子也在多项才能上兑现了对标 OpenAI o1-mini 的遵守。
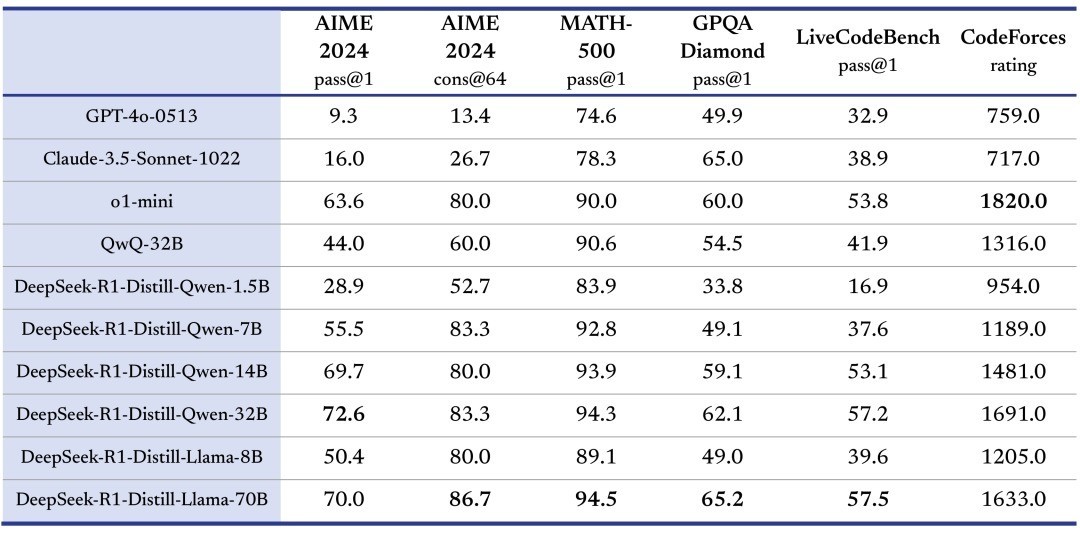
而这些蒸馏后的模子,咱们如故不错尝试在我方的造就上,腹地进行起初。
02. 两把杀手锏- MoE 羼杂大师模子DeepSeek-R1 的资本上风,便在其官方 API 职业订价中体现了出来:
每百万输入 tokens:1 元(缓存射中)/ 4 元(缓存未射中)
每百万输出 tokens:16 元
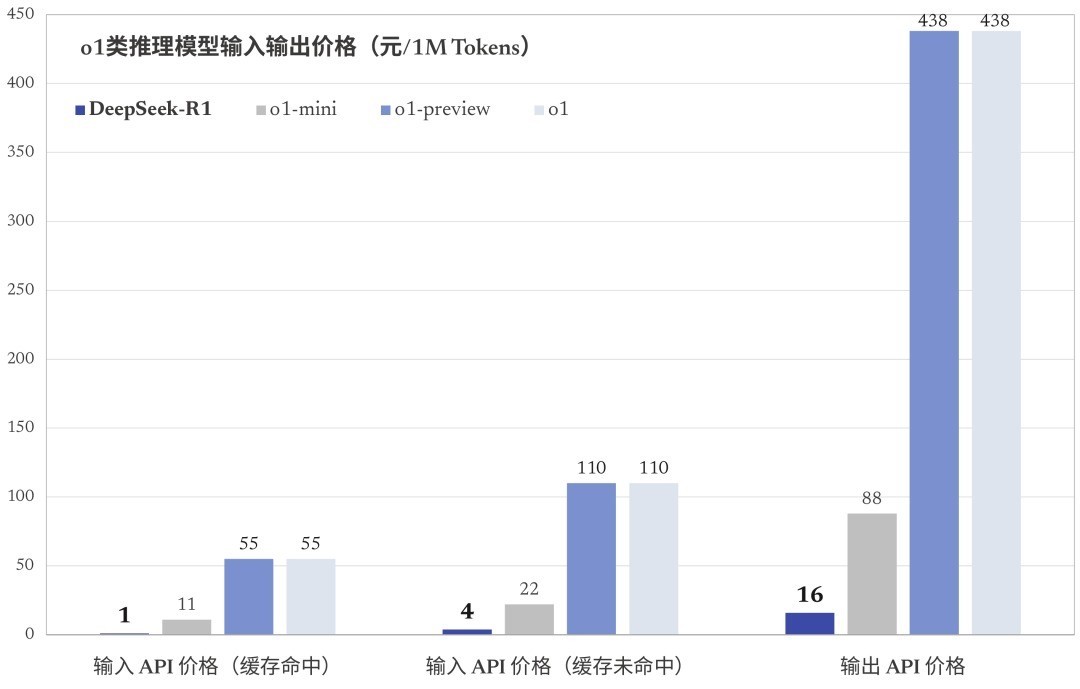
其输出 API 价钱,致使只是 ChatGPT o1 的约 3%,这就要聊到 MoE 羼杂大师模子了。
IT之家前边提到,DeepSeek-R1 是一款 671B 参数的模子,从传统的角度来看,起初起来毫不会放肆。
而 MoE 架构的中枢想想,其实就是将一个复杂的问题认识成多个更小、更易于管制的子问题,并由不同的大师网罗别离处理。
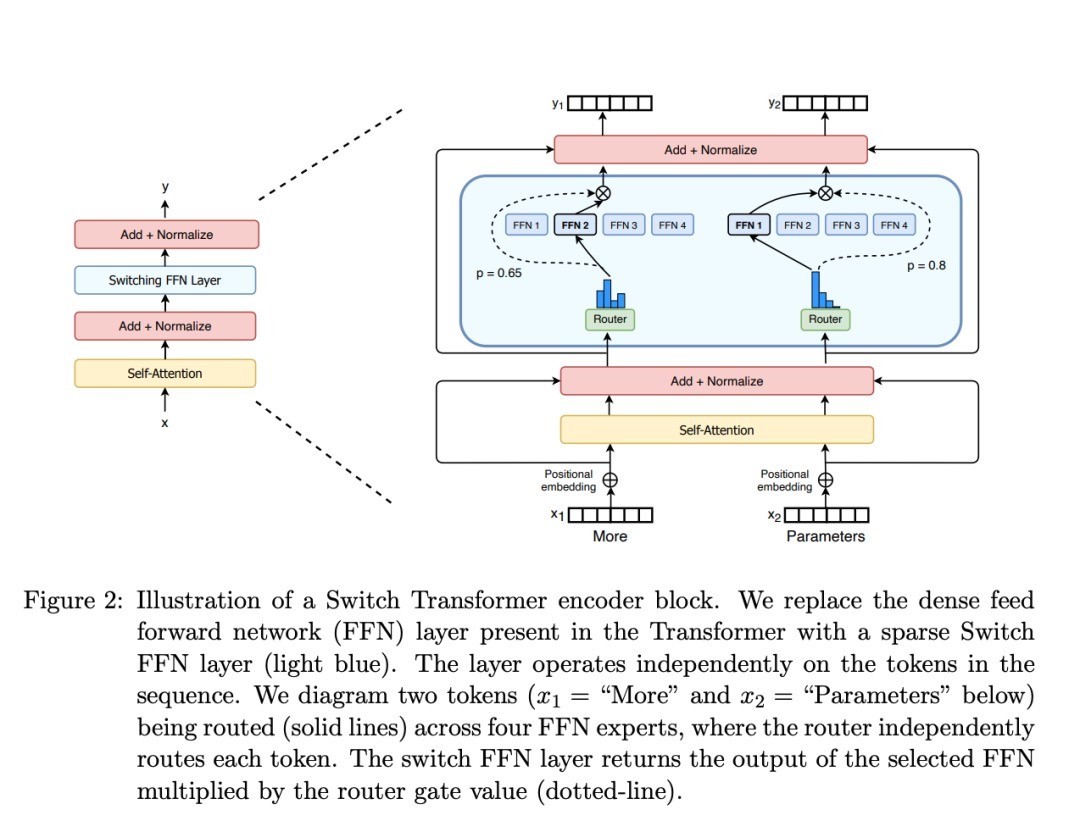
这么,当咱们向 MoE 模子输入辅导时,查询不会激活总共 AI,而只会激活生成反应所需的特定神经网罗。
因此,R1 和 R1-Zero 在回话辅导时激活的参数仅为 37B,不到其总参数目的十分之一,“让专科的东谈骨干专科的事”,推理资本大大裁汰。
其实,MoE 并不是一个新想法,最早发源于 1991 年的论文《Adaptive Mixture of Local Experts》。
不外这一想路的“腾飞”,还要比及 2023 年 12 月 Mixtral 8x7B 模子的推出。
外界精深以为 GPT-4 就使用了 MoE 模子,但关于如故形成“CloseAI”的 OpenAI 来说,其旗舰模子的好多期间细节,咱们无从得知......
- RL 强化学习传统的 AI 大模子熟谙,使用的是 SFT 监督微调历程,在用心策动的数据集上熟谙模子,教诲它们冉冉推理。
而 DeepSeek-R1 则使用 RL 强化学习的口头,十足依赖环境反馈(如如问题的正确性)来优化模子活动。
它也第一次证明了通过纯 RL 熟谙,即可进步模子的推理才能。模子在 RL 熟谙中自主发展出自我考证、反想推理等复杂活动,达到 ChatGPT o1 级别的才能。
这项期间,阐发咱们异日在熟谙的历程中,可能不再需要付出极为腾贵的资本,获取多量经过详备标注的高质料数据。
03. 多模态,补短板尽管 DeepSeek-V3 和 DeepSeek-R1 十分庞大,但他们还王人是名副其实的“废话语模子”,并不具有多模态的才能。
也就是说,咱们当今还没发把图片、音频等信息丢给他们,他们也不具备生成图片的才能,只可通过笔墨的神气来进行信断调换。
当今 DeepSeek 官方提供的文献上传才能,其实只是走了一遍笔墨 OCR 识别。
不外,就在 1 月 28 日凌晨,DeepSeek 开源了全新的视觉多模态模子 Janus-Pro-7B。
与以往的口头不同,Janus-Pro 通过将视觉编码历程拆分为多个孤立的旅途,治理了以往框架中的一些局限性,同期仍接纳单一的调处变换器架构进行处理。
这一解耦神气不仅有用缓解了视觉编码器在领路和生成历程中可能出现的冲突,还进步了框架的活泼性。
Janus 的发达稀奇了传统的调处模子,况兼在与任务特定模子的比较中也相同发达出色。凭借其或然、高活泼性和高效性的性情,Janus-Pro 成为下一代调处多模态模子的有劲竞争者。
其在 GenEval 和 DPG-Bench 基准测试中打败了 Stable Diffusion 和 OpenAI 的 DALL-E 3。
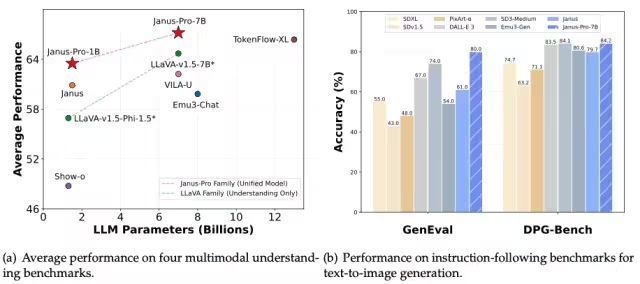

不外看成一款仅有 7B 参数的“小”模子,Janus-Pro 当今只可处理 384 x 384 分辨率的图像。
但咱们信服,这只是一谈开胃菜,咱们期待在新想路下,DeepSeek 异日多模态大模子的发达。
04. 除夜不眠夜DeepSeek 的爆火,让不少 AI 大模子领域的“友商”,王人没法无视这么一家“小公司”。
今天(1 月 29 日)凌晨,农历新年的钟声刚刚敲响,阿里通义团队带来了他们的“新年礼物”—— Qwen2.5-Max 模子。

通义千问团队,也在 Qwen2.5-Max 模子的先容中提到了 DeepSeek-V3。
近期,DeepSeek V3 的发布让公共了解到超大范围 MoE 模子的遵守及兑现口头,而同期,Qwen 也在研发超大范围的 MoE 模子 Qwen2.5-Max,使用越过 20 万亿 token 的预熟谙数据及用心贪图的后熟谙决议进行熟谙。
与业界最初的模子(包括 DeepSeek V3、GPT-4o 和 Claude-3.5-Sonnet)比较,Qwen2.5-Max 的性能发达也稀奇有竞争才能。
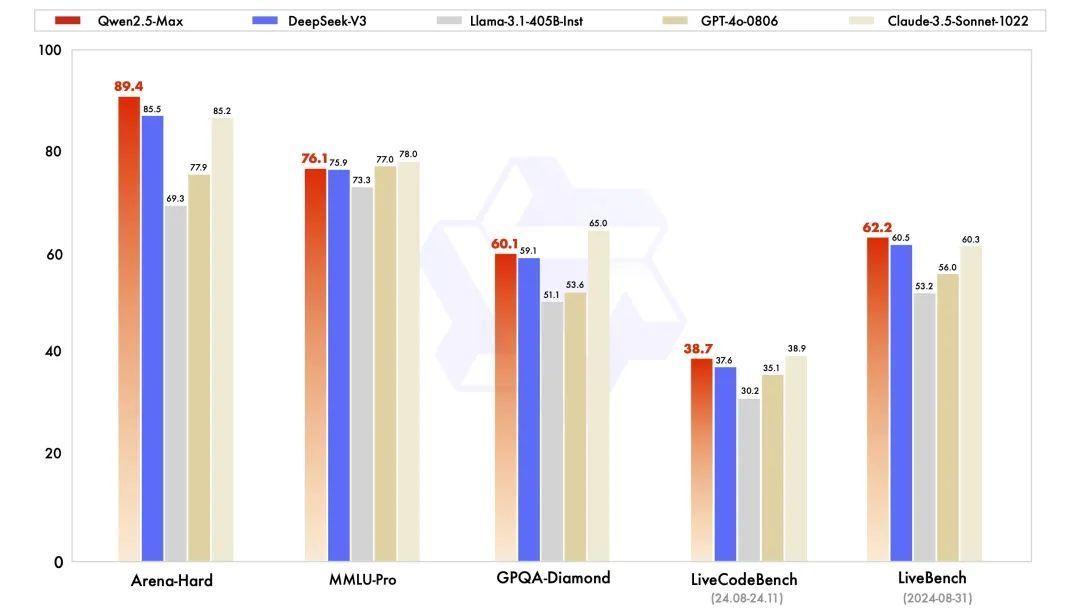
在基座模子的对比中,与当今最初的开源 MoE 模子 DeepSeek V3、最大的开源无边模子 Llama-3.1-405B 比较,Qwen2.5-Max 在大多数基准测试中王人展现出了上风。
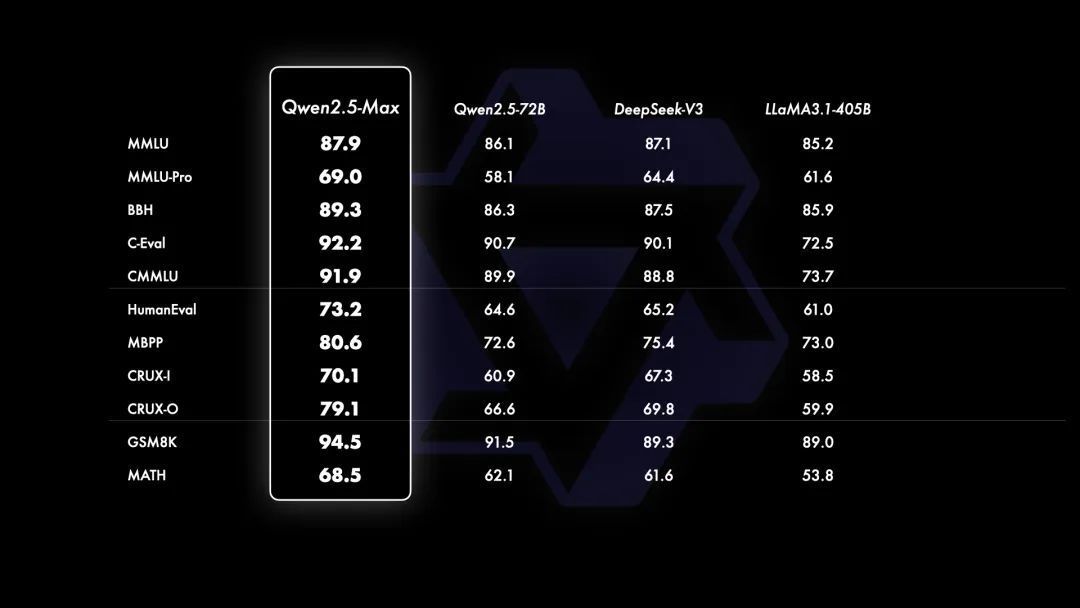
当今 Qwen2.5-Max 如故面向用户绽开,不外看成“Max”定位的模子,Qwen2.5-Max 暂未开源。

而与 DeepSeek-R1 的径直对决,咱们可能要比及异日新版的 QwQ、QVQ 模子。
OpenAI 的 CEO 阿尔特曼也对 DeepSeek-R1 进行了评价:

面临公共价钱上的诉苦,阿尔特曼也示意异日的 ChatGPT o3-mini 模子将会绽开给免用度户使用,Plus 会员则每天有 100 条央求的额度。
此外,新的 ChatGPT Operator 功能也将尽快向 Plus 会员绽开,而 OpenAI 的下一款模子也不会由每月 200 好意思元的 Pro 会员独占,Plus 会员就能用
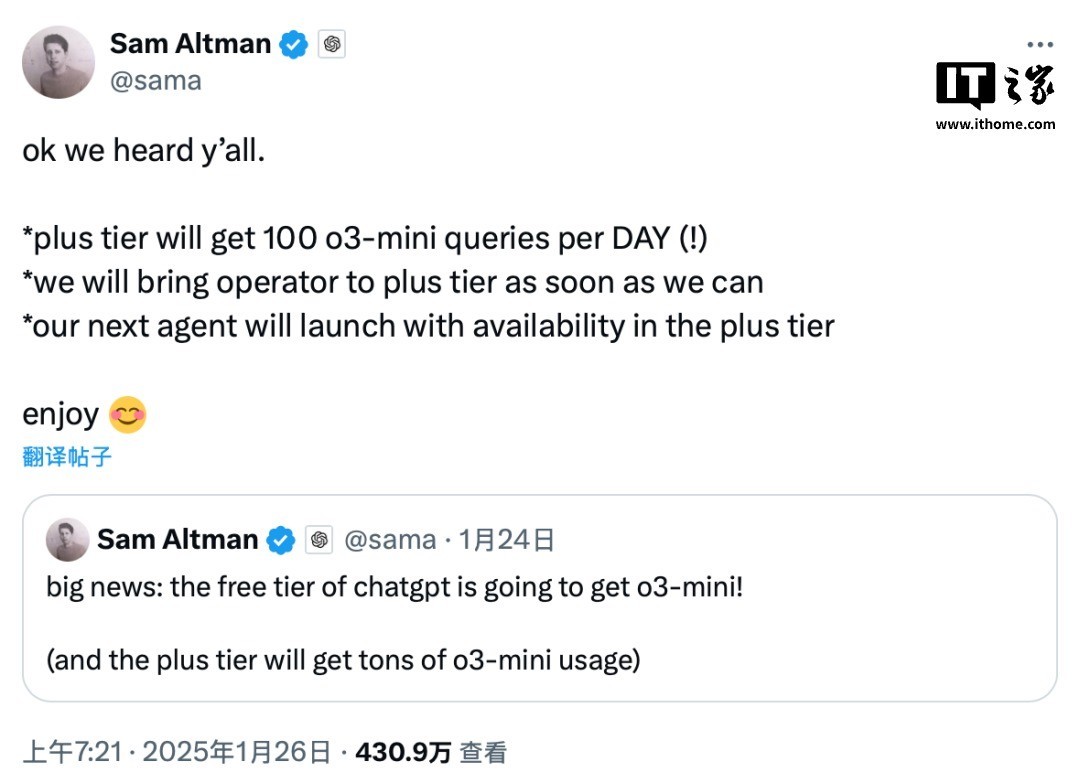
这究竟是来自于 DeepSeek 等竞争敌手的压力,如故 OpenAI 本人的资本优化,咱们不知所以。
咱们期待着在 2025 年,还会有哪些枢纽领域的冲破,AGI 通用东谈主工智能是不是也离咱们越来越近了。
